


Ensuring the original audio is accurately transcribed is essential in developing an automatic dubbing system. However, this is merely the first step in the process. Just as poor transcription can diminish the quality of the final product, an inaccurate or poorly executed translation can have equally detrimental effects.
Producing high-quality translations of the source material is surprisingly challenging. Languages are inherently complex, especially those with different linguistic roots. In addition, there are countless ways to express the same idea, which further deepens the complexity Emphasizing certain aspects to achieve a translation that flows naturally is certainly not an easy task.
This article introduces two solutions for creating high-quality translations. Both ways are effective. One offers superior translation quality but demands more hardware resources and operates at a slower pace. The other prioritizes speed, making it an excellent choice when time is a critical factor.
What Makes Translation Difficult?
Several important factors regarding pronunciation must be generally considered when translating text for an automatic dubbing system. The task becomes even more complex in this context for a crucial reason. The time it takes to pronounce the translated material needs to closely correspond with that of the original language. If the timing is off, it creates the awkward effect of mismatched lip movements. This is similar to watching subtitles that are out of sync with the dialogue. There are a few ways to address this issue.
Achieving the highest possible quality in dubbing requires a human touch in the process. The finest dubs are those where the translation matches the original material in terms of content, but not only. It also mirrors the way the dialogue is pronounced and delivered. This means that phonetics—the study of human speech sounds—must be carefully considered.
Phonetics is vital for understanding how words are articulated and perceived across different languages. In the context of dubbing, phonetics plays a significant role through a technique known as phonetic matching. Simply put, phonetic matching involves rephrasing the translated dialogue so that the spoken words in the target language align closely with the actor's mouth movements. This is particularly important for plosive consonants like "b," "p," and "m," where misalignments between lip movements and sounds are highly noticeable to viewers.
In addition to phonetic matching, other phonetic elements, such as prosody and syllable count and timing, require special attention toward seamless dubbing. However, their role is secondary in creating a dub of the highest quality.
There are certain libraries in Python available to be used for phonetic matching of our translation with the original text. However, their results are far from the quality a human can achieve. As a result, phonetic precision is often compromised in fully automated systems.
This limitation explains why movie dubbing and other forms of media translation are still not fully automatic. Therefore, until more advanced phonetic matching pipelines are developed, the best alternative is to ensure that translations, when pronounced, closely match the timing of the original text. However, depending on the source material, this compromise may lead to noticeable discrepancies. For example, the speaker's mouth movements may not perfectly match the translated audio. This is an inevitable compromise when working toward a fully automatic dubbing system.
Fortunately, most translation models naturally align the length of the translated text with that of the original. While this alignment is not always an intentional design choice by the creators of the model, it often results from the characteristics of the training data used to develop these models. Regardless of the intent, this feature simplifies the task of building an automatic dubbing pipeline, so we gladly take advantage of it.
Article continues below
Want to learn more? Check out some of our courses:
Types of Translation Models
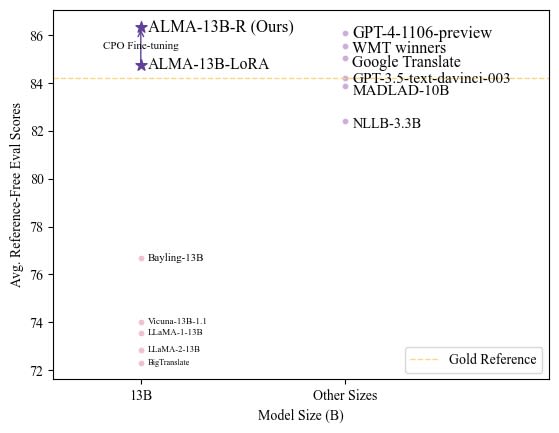
There are many models that can produce high-quality translations. A performance comparison of these models can be seen in the image below.
As in many other fields, Large Language Models (LLMs) dominate translation tasks. Their complexity, extensive training data, and processing power enable them to deliver superior results when it comes to translating text. It is important to note that most of the top models shown in the image, aside from OpenAI's GPT model, are LLMs fine-tuned specifically for translation purposes. As a result, they may not serve as high-quality general-purpose chatbots anymore. However, our primary focus here is their ability to translate from one language to another.
Among these top models, Google Translate is arguably the most well-known. It has become the "de facto" translation tool for many users unfamiliar with deep learning. Its seamless integration with Google's Search Engine, the most popular search engine today, also contributes to its widespread use. Therefore, Google Translate will be one of the two models to consider for our automatic dubbing system.
For the second model, let's select what is widely regarded as the best available: the recently introduced ALMA-13B-R model. This model seems to produce translations of the highest possible quality. However, as we will explore later, this model's superior accuracy comes at the cost of significantly slower performance compared to Google Translate.
Main Features of Google Translate
Almost everyone is capable of accessing Google Translate via a web browser. However, many are unaware that accessing it from Python is relatively simple if we utilize the deep-translator library. Marketed as a flexible and free tool for translating text, this library allows users to interact with Google Translate from Python.
Moreover, it provides users with a variety of other translators, including ChatGPT. However, many of these other translators require users to create accounts and obtain API keys. This can be inconvenient when a quick translation solution is needed. Therefore, we will stick with Google Translate, which outperforms the other options.
To install the deep-translator library, simply run the following line in the terminal: pip install deep-translator. After installation, using Google Translate becomes remarkably easy, requiring just two lines of code to translate text.
For instance, let's translate this sentence from English to French:
This is a tutorial on creating an automatic dubbing system
To translate this text using Google Translate and the deep-translator library, we can run the following lines of code.
from deep_translator import GoogleTranslator
original_text = "This is a tutorial on creating an automatic dubbing system"
translator = GoogleTranslator(source='en', target='fr')
translated_text = translator.translate(original_text)
The translation we get as a result of running this code is:
Ceci est un tutoriel sur la création d'un système de doublage automatique
The translation process is almost immediate and produces a high-quality result.
Main Features of ALMA-13B-R
The original ALMA (Advanced Language Model Based Translator) model was released in 2023 as a response to conventional supervised encoder-decoder models. Before its release, it was fair to say that although LLMs sparked a revolution in Natural Language Processing, they initially struggled to excel at translating from one language to another. Standard encoder-decoder models seemed to perform much better when it came to it.
ALMA changed that narrative. Based on the LLaMA-2 model, it was the first LLM (technically a modified version of one) that managed to achieve competitive results regarding translation quality. Since its initial release, the ALMA model has undergone constant improvements. The latest version, ALMA 13B-R model, now ranks as the top LLM translation model. This variant was specially trained to achieve the high-quality results that we see today. Released in 2024, it is entirely free and available under the MIT license.
The easiest way to use this model is to download and run it using the transformers library. It is a library that provides APIs and tools to easily download and use, or even further train, state-of-the-art pre-trained models. To install it, simply run pip install transformers in the terminal and you are good to go.
Since we are building an automatic dubbing pipeline, instead of just using the ALMA model, let's create a Translator class. That will allow us to use any other model that we can download from the transformers library, as they all share a similar interface. For added flexibility, users can also opt for the Google Translate model from the previous chapter. I will use the PyTorch Deep Learning framework to run my Deep Learning models:
# Create general translator class
class Translator:
def __init__(self, translator):
"""
Initialize with a translator instance.
Args:
translator: An instance of a translator model or library.
"""
self.translator = translator
def translate(self, sentence, source_language="English", target_language="French", **kwargs):
"""
Translate a sentence using the provided translator.
Args:
sentence (str): The sentence to translate.
source_language (str): The source language (default is "English").
target_language (str): The target language (default is "French").
**kwargs: Additional arguments to pass to the translator's translate method.
Returns:
str: Translated text.
"""
# Check if the translator has a 'translate' method that matches the expected signature
if hasattr(self.translator, 'translate'):
if isinstance(self.translator, GoogleTranslator):
# For GoogleTranslator, use the existing method without additional arguments
return self.translator.translate(sentence)
else:
# For other translators like ALMA13BTranslator, pass the additional arguments
return self.translator.translate(sentence, source_language, target_language, **kwargs)
else:
raise ValueError("The provided translator does not have a compatible 'translate' method.")
The code above defines a Translator class that serves as a general wrapper for different translation models or libraries. Its primary purpose is to provide a unified interface for translating sentences, regardless of the underlying translator's implementation details. To be more precise, the translate method is the one that provides a unified way to translate a sentence using the underlying translator instance.
When building the class, English and French were set as default languages, assuming translations would be from English to French. However, you can specify any other language pair as arguments if needed.
At this point, we can only use this general Translator class to translate using the Google Translate model from deep-translator. To do so, I can run the following code:
# Define translator
translator = Translator(GoogleTranslator(source="en", target="fr"))
# Define text to translate
text = "This is a tutorial on creating an automatic dubbing system"
# Translate text
translated_text = translator.translate(text)
By doing so, I will achieve the same result as before. Now, to use the ALMA model, I have to build another class that can interact with the Translator class I built earlier. That class will look like this:
import torch
from transformers import AutoModelForCausalLM
from transformers import AutoTokenizer
class ALMA13BTranslator:
"""
A class to handle translation tasks using a pre-trained ALMA language model.
Attributes:
model (AutoModelForCausalLM): The pre-trained language model for causal language modeling.
tokenizer (AutoTokenizer): The tokenizer associated with the language model.
"""
def __init__(self, model_name="haoranxu/ALMA-13B-R"):
"""
Initializes the ALMA13BTranslator with a specified pre-trained model.
Args:
model_name (str): The name or path of the pre-trained model to use.
Defaults to "haoranxu/ALMA-13B-R".
Initializes:
model: Loads the pre-trained causal language model with specified model name.
tokenizer: Loads the corresponding tokenizer for the language model.
"""
self.model = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype=torch.float16, device_map="auto")
self.tokenizer = AutoTokenizer.from_pretrained(model_name, padding_side='left')
def translate(self, sentence, source_language="English", target_language="French"):
"""
Translates a given sentence from a source language to a target language.
Args:
sentence (str): The sentence to be translated.
source_language (str): The language of the input sentence. Defaults to "English".
target_language (str): The language to which the sentence will be translated. Defaults to "French".
Returns:
str: The translated sentence in the target language.
Note:
This method uses beam search with sampling to generate translations,
making the translation process stochastic.
"""
prompt = f"Translate this from {source_language} to {target_language}:\n{source_language}: {sentence} \n{target_language}:"
input_ids = self.tokenizer(prompt,
return_tensors="pt",
padding=True,
truncation=True).input_ids.to('cuda')
with torch.no_grad():
generated_ids = self.model.generate(input_ids=input_ids,
num_beams=10,
max_new_tokens=150,
do_sample=True,
temperature=0.6,
top_p=0.9)
outputs = self.tokenizer.batch_decode(generated_ids, skip_special_tokens=True)
return outputs[0]
This class loads the ALMA 13B-R model using the Auto Classes from the transformers library. The AutoModelForCausalLM and AutoTokenizer classes both allow users to use the from_pretrained method. This enables users to load the model and the necessary tokenizer for the model to function automatically, using just the model name.
The translate method of the class is responsible for performing the actual translation. To be more precise, we first define a prompt that we will send to the LLM, requesting a translation from one language to another. Next, we specify how the tokenizer will process the prompt. The code here is mostly boilerplate, commonly used across models in the transformers library. Finally, we need to define how the model will generate the response, which involves several important arguments:
- input_ids - instructs the model to use the input generated by the tokenizer
- num_beams - the model uses beam search with 10 beams, which means it keeps track of 10 possible translations and picks the best one based on probability
- do_sample - this introduces randomness into the translation process, making the output less deterministic and more creative
- temperature - controls exactly how random or "creative" the sampling process is (lower values make the output more predictable, higher values make it more diverse)
- top_p - a technique called nucleus sampling, which limits the model to select from the top 90% of most likely words at each step, preventing it from considering improbable words while still allowing some diversity in the translation
To use this class together with our general Translator class, we can run the following code:
# Define translator
translator = Translator(ALMA13BTranslator())
# Define text to translate
text = "This is a tutorial on creating an automatic dubbing system"
# Translate text
model_answer = translator.translate(text, source_language="English", target_language="French")
start_index = model_answer.rfind("French:") + len("French:")
translated_text = model_answer[start_index:].strip()
As can be seen, even after the model returns the translation, there is still some work to be done. The model will return an answer such as :
Translate this from English to French:
English: This is a tutorial on creating an automatic dubbing system
French: Ce tutoriel montre comment créer un système de doublage automatique
Since we receive this answer from the model, we need to do some work to extract only the French translation from its output.
In this article, we explained in detail how to perform translation using Deep Learning and create the necessary classes to integrate this process into our final automatic dubbing pipeline. We used Google Translate and the ALMA 13B-R model to translate a sentence from English to French. Even though we got two different translations, they convey the same meaning using different words. Using Google Translate via the deep-translator library produces translations more quickly, whereas the ALMA model takes slightly longer but arguably offers translations that better reflect the original sentence's tone and meaning. In the following article of this series, we will focus on creating a Text-To-Speech model that will generate dubbed audio based on our translated sentences.

