



One of our previous articles already explored the fascinating world of AI-driven music generation. An in-depth analysis of the evolution of music generation models was provided, highlighting the most prominent ones. In this article, however, we will focus on one specific model: the MusicGen model.
MusicGen stands out as a prime example of AI-assisted music creation. It allows users to generate entirely new, synthetic music using only textual prompts. This article will thoroughly explain how the MusicGen model works. Additionally, it will demonstrate how easy it is to implement the model using the HuggingFace library from Python.
What Is MusicGen
MusicGen is a free, highly advanced AI music generation model developed by Meta. Upon its release, it quickly gained popularity for enabling users to generate unlimited copyright-free music. Its straightforward interface has significantly contributed to its growing popularity. Users simply need to write descriptions of the desired music, making it accessible and easy to use. As a result, MusicGen's generated music has been adopted by numerous companies across various industries. In addition to its user-friendly interface, the revolutionary architecture of MusicGen is noteworthy. Unlike many of its predecessors, MusicGen approaches music generation in a novel way.
For a long time, the most advanced models in the field were GANs (Generative Adversarial Networks). These consist of a generator and a discriminator trained in opposition, where the generator creates music, and the discriminator distinguishes between real and generated music. A GAN is considered trained only when the discriminator can no longer tell the difference. However, GANs are notoriously difficult to train and prone to problems, involving multiple models by design.
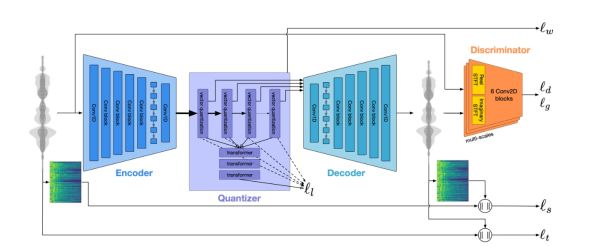
In contrast, MusicGen uses a unique single-model architecture, differentiating it from traditional GAN-based methods. Specifically, MusicGen is a single-stage Transformer model that similarly approaches music generation to text analysis in Natural Language Processing (NLP). In NLP, advanced tokenizers convert text into numeric representations for model training. Similarly, MusicGen employs a special audio tokenizer called EnCodec to create numerical representations of music. Afterward, these are used to train the model.
How Does EnCodec Tackle Audio Tokenization
You might have encountered music visually represented as waveforms, even if you are not particularly familiar with music generation or music in general. These waveforms are usually displayed when playing music, as most music players show the waveform of the currently playing track.
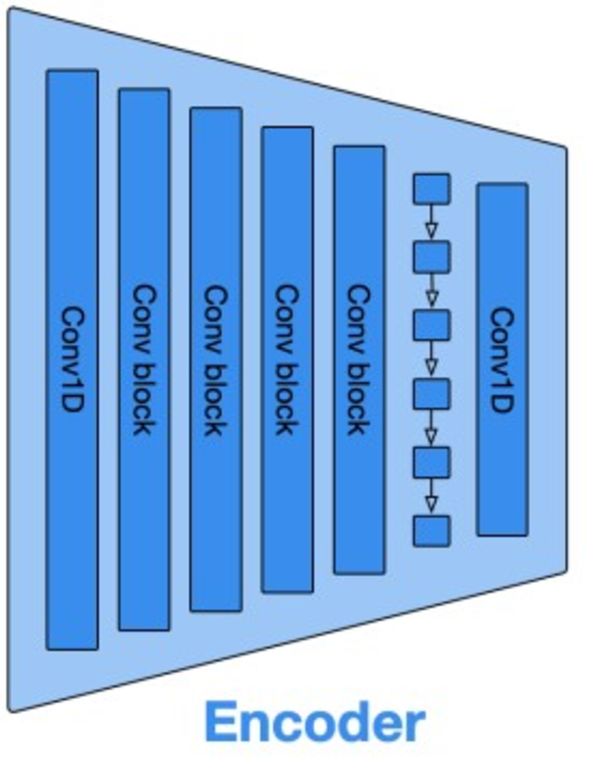
Our challenge lies in representing this waveform with numbers, for our model to be able to process it. These waveforms are commonly represented with vectors. However, these vectors usually end up being quite big, which is a problem. For instance, to represent one second of audio at a 32 kHz sampling rate, which is a standard sampling rate for audio, we need to use a vector of size 32 000. Handling vectors of this length is impractical, therefore we need a more efficient way to represent our waveforms. To address this, we will use the EnCodec audio tokenizer. EnCodec is a convolutional encoder-decoder model trained specifically to compress any kind of audio and reconstruct the original signal with high fidelity. The model consists of three main parts:
- encoder
- quantizer
- decoder
The encoder part of the model compresses raw audio data using multiple convolutional layers. These layers apply various filters to capture essential audio features, like pitch, tone, and timbre. Simultaneously, the encoder downsamples the input, reducing the number of data points. This process compresses the original 32,000-dimensional vector into a lower-dimensional form without losing critical information. This compact representation is known as the latent representation.
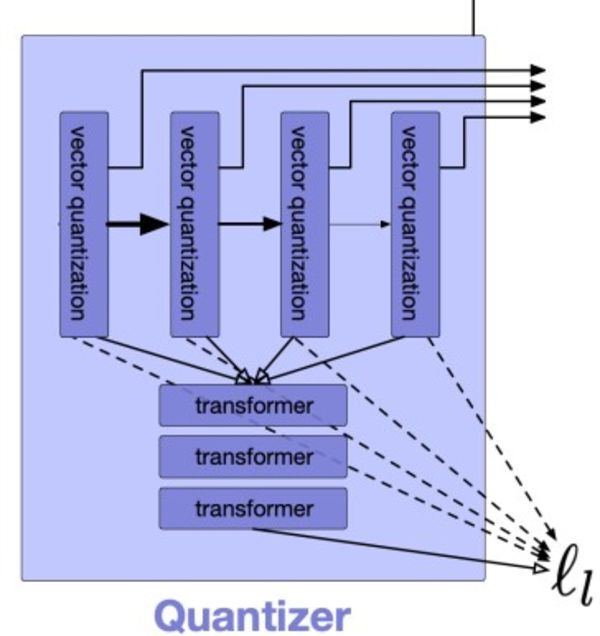
These latent variables are quantized into discrete tokens using the Quantizer. The aim of dimensionality reduction goes beyond just compressing data. It also aspires to create precise representations where patterns are automatically identified and stored for later reconstruction. The way quantizers work is quite simple.
An encoded audio sample, for example, size 128, is input to the quantizer. The quantizer has a codebook containing vectors of the same size. The encoded audio vector is compared to each vector in the codebook. The closest match is selected, and the input vector is represented by the index of this matching vector in the codebook.
This approach enables efficient audio data compression by storing only the indices of the closest codebook vectors rather than high-dimensional vectors. As a result, it reduces the data storage and transmission requirements, making audio processing and storage more efficient.
Unfortunately, this approach is not perfect. When the number of potential input vectors grows, accurately representing all of them requires an excessively large codebook. Such a large codebook would be impractical for efficient storage and processing. Essentially, the more different music you want to accurately encode, the bigger the codebook needs to be. The EnCodec algorithm solves this using so-called Residual Vector Quantization (RVQ). RVQ solves this by using multiple quantizer layers, each focusing on the errors made by previous layers.
The first layer will quantize the input vector, leaving a residual (the difference between the input vector and its quantized version). Afterward, each subsequent layer will quantize the residual from the previous layer. Therefore, by adjusting the number of layers we can adjust the balance between compression accuracy and computational efficiency.
Finally, the decoder takes the compressed signal and reconstructs it into a stream of audio data. The discriminator component of the model then compares the reconstructed audio to the original. Through iterative training, the model aims to reduce the difference between the two, thereby effectively training the EnCodec algorithm.
In MusicGen, EnCodec serves as the tokenizer, processing multiple streams of tokens to represent audio data. The model utilizes multiple parallel streams of discrete tokens. Each stream captures different aspects of the audio signal, such as various frequency bands or residuals from quantization steps. This method enables detailed and flexible modeling of complex audio signals. The parallel streams are processed and combined to reconstruct high-fidelity audio. This technique facilitates efficient and high-quality music generation. Specifically, the model employs four codebooks to achieve this.
Article continues below
Want to learn more? Check out some of our courses:
What Is AudioGen: The Heart of MusicGen
The core of MusicGen is AudioGen, even though the EnCodec algorithm is essential for transforming audio signals into a format that Deep Learning models can process AudioGen, an autoregressive Transformer language model developed by Meta, generates audio samples based on text inputs. It exclusively uses acoustic feature tokens produced by the EnCodec tokenization algorithm. To generate music, the model conditions the acoustic information. This is usually done using text, but users can also input an audio sample as a reference.
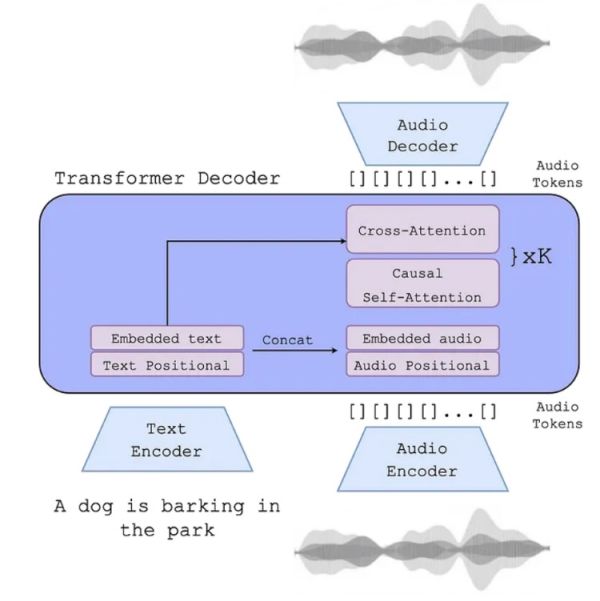
The process of generating music with AudioGen begins with the user providing a textual description. This text is encoded using a text encoder such as T5, FLAN-T5, or CLAP. The data gets encoded into a tensor C. A tensor is a multi-dimensional array of numbers. Tensors generalize vectors and matrices to higher dimensions. For instance, a vector is a one-dimensional tensor, a matrix is a two-dimensional tensor, etc. At the same time, we perform audio tokenization using the EnCodec model to generate multiple streams of discrete tokens.
The generation process begins with an initial token, often a special start-of-sequence token (<SOS>). This indicates the start of the audio sequence. This token by itself does not represent a particular sound. Instead, it is used as the starting point of the autoregressive generation process. First, we feed the <SOS> token and the conditioning tensor C in the model. As a result, the model will generate the first audio token based on this. Afterward, the whole process repeats. However, this time we also feed the first token that was created, instead of feeding just the <SOS> token and the conditioning tensor C. At this point, we have the <SOS> token and two additional tokens. This autoregressive process repeats until the desired length of the audio sequence is achieved.
After generating the complete sequence of tokens, we use the EnCodec model to decode these tokens into a continuous audio waveform. Next, the tokens from different streams are combined and processed to reconstruct the final audio output. This process ensures that the generated music aligns with the textual description and any provided audio references. It also ensures high fidelity and coherence in the final audio.
How Does MusicGen Generate Music This Fast
The autoregressive nature of MusicGen made it essential for its creators to focus on maximizing the model’s speed. To achieve the necessary speed, the creators took advantage of various techniques designed to speed up the token prediction process. All of these techniques were unified by a single strategy: the use of parallelization to improve the efficiency of token prediction.
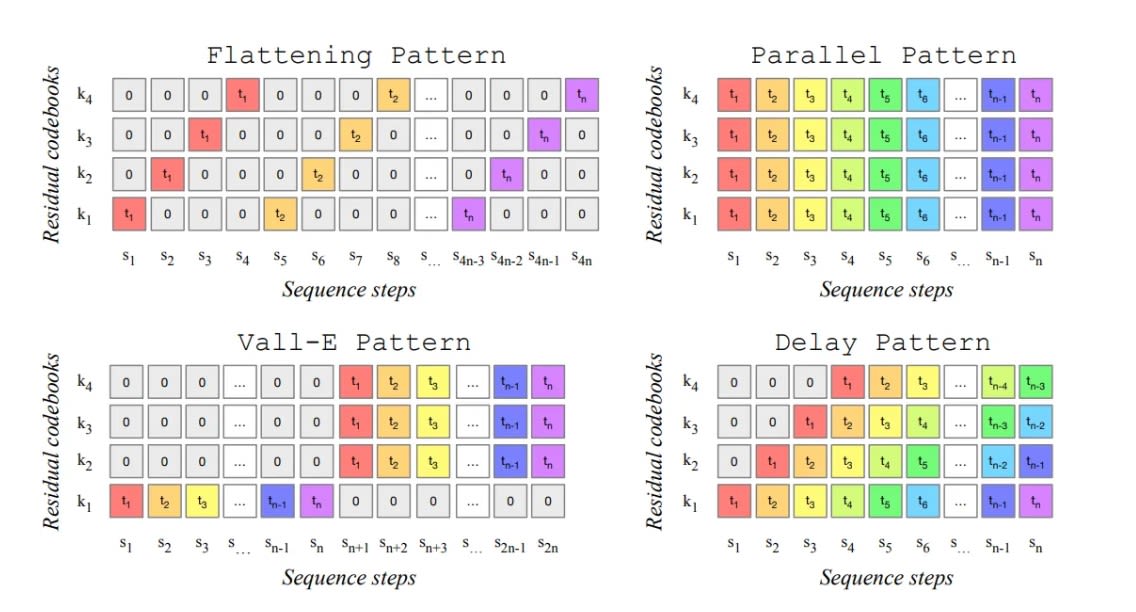
The MusicGen model used four codebooks in total. This meant that for every timestep the model needed to produce acoustic tokens for each of the codebooks. This is problematic because the model was designed to produce music at a sample rate of 50 Hz. This means that to produce a 30-second audio clip, we would go through 1500 timesteps (30 seconds times 50 frames per second). The key to speeding up the process was discovering methods for parallelizing the token prediction task. The creators of the model demonstrated four different approaches to simultaneously model these multiple streams of tokens from various codebooks.
The flattening pattern combines tokens from all layers into one long sequence, processing them sequentially. While this method keeps the dependencies between tokens intact, it also increases computational complexity due to the longer sequence length.
The parallel pattern predicts tokens in all layers simultaneously at each timestep. This reduces the overall time needed for prediction. It speeds up the process but may struggle with maintaining dependencies between layers.
The Vall-E pattern first predicts tokens in the top layer serially. Afterward, it estimates tokens in the remaining layers in parallel. This approach balances maintaining dependencies in the top layer while improving efficiency in the lower layers.
The delay pattern shifts the arrangement of tokens in the time direction, allowing for parallel token predictions at different time steps. This technique reduces the waiting time between predictions, improving efficiency while maintaining quality.
By employing these different patterns, the creators of the network managed to greatly boost the model's speed. As a result, it became highly competitive for generation speed while still keeping its quality at an exceptionally high level.
How to Implement MusicGen in Python
There are different ways you can implement MusicGen in Python. The two most popular ways are using the Audiocraft library from Meta, and using the HuggingFace library. In both cases, you can run the model with just a few lines of code.
This article will explain how to run the model using the HuggigFace library. Before we get into it, it must be noted that these models can be quite demanding in terms of hardware. It is recommended to have a good GPU to run these on. Otherwise, the entire process will be significantly slower.
To use HuggingFace to run the model, you first need to install the transformers library and the scipy library. You can easily do this using pip. Simply run the following command in your console while in your working environment:
pip install --upgrade transformers scipy
After installing these two libraries, we can use the model to generate music. The Transformers library offers us two ways of running the model. The simplest way is to use the Text-to-audio (TTA) pipeline, therefore we proceed like this. At first, we import the libraries that are going to be used. Then, we create a TTA pipeline:
from transformers import pipeline
import scipy
# Create the pipeline
music_gen = pipeline("text-to-audio", "facebook/musicgen-large")
On HuggingFace, you can find four different versions of the MusicGen model:
- small
- medium
- large
- melody
The smaller models run faster but produce lower-quality results. The larger models run slower but produce higher-quality results. Out of these four models, only the melody model is not available as is. This one requires the installation of the Audiocraft library from Meta, which won't be covered here. For now, let us use the large model.
Keep in mind that the first time you run the pipeline creation code, the process might be slower. This is because you need to download the model in the background. After that, as the model is already downloaded, the process will be much faster.
To speed up the entire process, you can use the small model instead. It downloads faster and speeds up the music creation process.
Next, we can use the model to generate music based on a certain text input. Let us ask for smooth jazz music, using this prompt:
"Generate a smooth jazz piece reminiscent of classic elevator music. The track should feature soft saxophone melodies, gentle piano chords, and a relaxed double bass line, creating a calm and sophisticated ambiance. The tempo should be slow to medium, with a soothing and mellow vibe throughout."
Let us write that in code:
# Define prompt for audio generation
prompt = """Generate a smooth jazz piece reminiscent of classic elevator music. The track should feature soft saxophone melodies, gentle piano chords, and a relaxed double bass line, creating a calm and sophisticated ambiance. The tempo should be slow to medium, with a soothing and mellow vibe throughout."""
# Generate music
music = music_gen(prompt, forward_params={"do_sample": True})
Finally, we need to save the music we just created, so we can listen to it. To do this, we can use the scipy library. Run the following code to save the created music as a WAV file:
scipy.io.wavfile.write("musicgen_out.wav",
rate=music["sampling_rate"],
data=music["audio"])
What if You Don't Have a Strong GPU
Unfortunately, without a strong GPU, you may not be able to run the model on your PC. To be more precise, running any version of the model will probably take too long. In that case, what you can do is follow this link:
https://huggingface.co/spaces/facebook/MusicGen
This link leads to a demo of MusicGen, hosted on HuggingFace. It is certainly not as flexible as running a model on your own. For instance, it will always generate samples that are 15 seconds long. However, it still allows you to use their hardware to run the model. Generating a 15-second sample takes approximately one minute, maybe a bit more. This way, you will at least be able to see how MusicGen works, even if you are unable to run it on your PC.
In this article, we continue our previous discussion on AI music generation. This time the focus is on MusicGen, one of the leading AI models for music creation. Even better, this model is currently available for free. This was a detailed overview of the model's architecture and an elaboration of its functionality. Moreover, the article provided a useful demonstration of how to run MusicGen on your computer.

