


Table of Contents
The biggest challenge with using Machine Learning (ML) models in Natural Language Processing (NLP) is how to represent text data to computers. This requires solving two problems: converting text to numbers since computers only work with numbers and preserving the relationships between different words.
- How to Use Machine Learning to Automate Tasks
- What Are the Most Popular Machine Learning Service Tools in 2023?
For example, if you convert a word into a series of numbers, how do you make sure that the series of numbers that represents a word like “tiny” will carry the opposite meaning of “large” while still holding a similar meaning to the word “small”? These complex relationships easily defined between words are hard to define between multiple series of numbers. To address this issue of word representation, word embeddings have emerged as the most effective way to represent text data with numbers.
In this article, I will focus on how word embeddings work by first talking about how the basics of analyzing human language works.
What Are the Basics of Analyzing Human Language?
Human language can be thought of as a special type of system that we use to convey meaning and express our thoughts, feelings, and ideas to each other. There is a lot of nuance to how we use language. A great example is sarcasm: saying one thing and meaning the exact opposite. And while understanding basic concepts is second nature to you, computers work by following rules that tell them what to do in each situation. Because there is an infinite number of ways you can use words, it is impossible to create a separate set of rules for each possible word combination. Instead, you can create models that break down human language into characteristics that are much easier for a computer to analyze.
There are various approaches to modeling human language, but the most widely adopted method is through synchronic models. Synchronic models represent language as a hierarchical set of language characteristics at a particular point in time, without focusing on how the language has evolved to get to that point. Synchronic models categorize language characteristics into different categories. The most important characteristics of human language that are analyzed using synchronic models are:
- Syntactic Characteristics
- Morphological Characteristics
- Lexical Characteristics
- Semantic Characteristics
- Discourse Characteristics
Syntactic characteristics pertain to the set of rules that dictate how words are arranged and combined to form phrases and sentences in a language. Put simply, they are used to examine the grammatical structure of a language.
Morphological characteristics describe how words are constructed and modified in a language, specifically with regard to their internal structure and the addition of affixes. For example, the word "run" is a morpheme which carries an independent meaning and can be modified by adding suffixes such as "-er" to form the word "runner.“
Lexical characteristics refer to the properties of words and their meanings in a language. These include vocabulary and semantics, as well as how words are used to convey meaning in communication. One example of a lexical characteristic is homonymy, or the relationship between words that have different meanings and spellings but are pronounced the same, such as “site,“ which means a place, and “sight,“ which means vision. Both are pronounced the same, but have different meanings.
Semantic characteristics deal with the meaning and interpretation of words, phrases, and sentences within a language. Semantics focuses on how words and sentences convey meaning and how meaning is perceived by speakers and listeners. Several significant characteristics within semantics include synonyms (different words with the same meaning, such as “good” and “fine”), antonyms (words with opposite meanings to one another, such as “hot” and “cold”), and hyponyms (words that specify further than a general word, such as “cat” is a hyponym of “animal”).
Discourse characteristics refer to the way language is used in longer stretches of communication, such as conversations, narratives, and speeches. Discourse analysis examines not only the structure of individual sentences and words but also the way these words are organized in the larger context of topics. For example, discourse comes in the form of descriptive, narrative, expository, and argumentative. Analysis of discourse takes the context of a larger body of text and interprets the meaning behind the words used to determine whether it’s descriptive or argumentative.
Word representations can be ranked based on how many of these language characteristics they can capture and to what extent. In the past, word representations were often limited and could only capture a few basic characteristics. However, word embeddings have significantly improved the representation of language by capturing multiple language characteristics simultaneously.
Article continues below
Want to learn more? Check out some of our courses:
Why Do We Need Word Embeddings?
Before word embeddings, word representations were created mostly through the use of statistics and were based on counting how many times a word appeared in some text. For example, one of the methods that was used was the Bag-of-words method. In this method, the text is treated as a "bag" of individual words, and the frequency of each word in the text is counted and represented as a numerical vector. This vector can then be used as input to various Machine Learning algorithms. This Bag-of-words method managed to capture some lexical and semantic characteristics, but not much else.
For example, it could tell that some words are connected because they often appear in the same sentence. However, this approach was unable to capture the context in which those words were used. While counting how many times words appeared in different sentences could establish a connection between two words, the nature of that relationship would be lost.
Let's say that I want to feed the two following sentences to a ML model:
- I drive a red car.
- I want to drive a blue car.
My goal is to represent these two sentences with numbers so that my ML model can use them for training. If I use the Bag-of-words method to represent them with numbers, I will end up with a representation that looks like this:
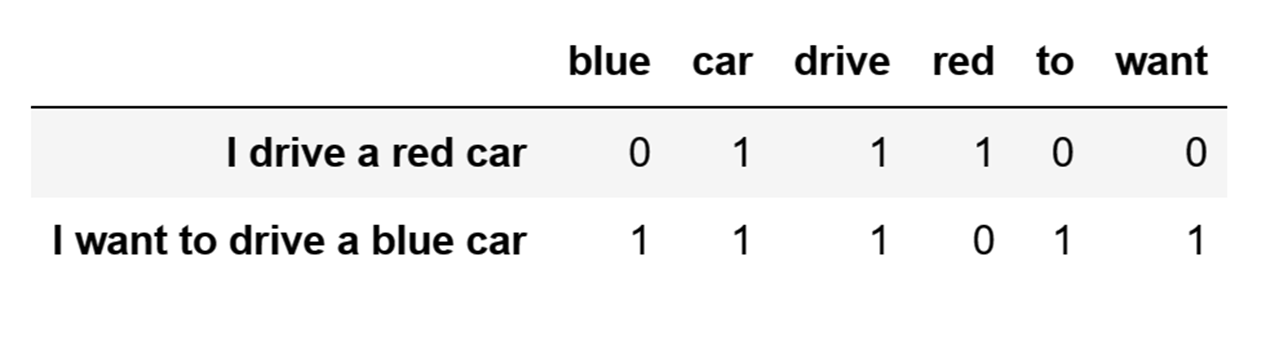
Words represented by numbers using the Bag-of-words method to train a Machine Learning model to analyze words in a sentence.
Image Source: Edlitera
In the image above it is evident that I successfully converted my text data to numbers. Additionally, some language characteristics may be recognized by my model. For instance, an ML model could identify that the words "car" and "drive" appear in the same sentence, but it may not be able to capture more complex language characteristics.
However, if you take a look at the values in the "blue" and "want" columns you will notice that they are identical, which is not ideal since it means that my model doesn't actually understand the difference between these two words that appear only in the second sentence is.
Apart from the limitations in capturing language characteristics, another issue with these older methods of creating word representations is that they can result in sparse datasets. For example, the Bag-of-Words method creates an additional feature for every unique word that appears in the text you are processing. While this may not seem problematic in the example above, where there are only two sentences and a small number of unique words, in practice, when working with larger texts, using these methods to represent words can lead to very large and sparse matrices.
In layman's terms, your dataset becomes extremely large while also being predominantly filled with zeros. This is problematic not only because it will decrease the performance of your model (because it can't identify any patterns in a dataset full of zeros) but it will also make the training process itself longer. So not only do you get worse results, it also takes you longer to get those worse results.
At this point, you may be wondering what could help you capture relationships between words more effectively and reduce the number of zeros in your dataset. Well, this is where word embeddings come in handy.
What Are Word Embeddings?
Word embeddings are the modern way of representing text data. The main concept behind word embeddings is that words used in similar contexts tend to have similar meanings, and thus their vectors should also be pretty similar.
So, how do you represent words if you can't do so with sparse vectors of ones and zeros? Instead, you use dense vectors, which are vectors in which most of the values are non-zero. In other words, the vector contains a high proportion of non-zero values relative to its length. For example, a dense vector of length 10 might contain 9 non-zero values and only one 0.
Let's take a look at an example:
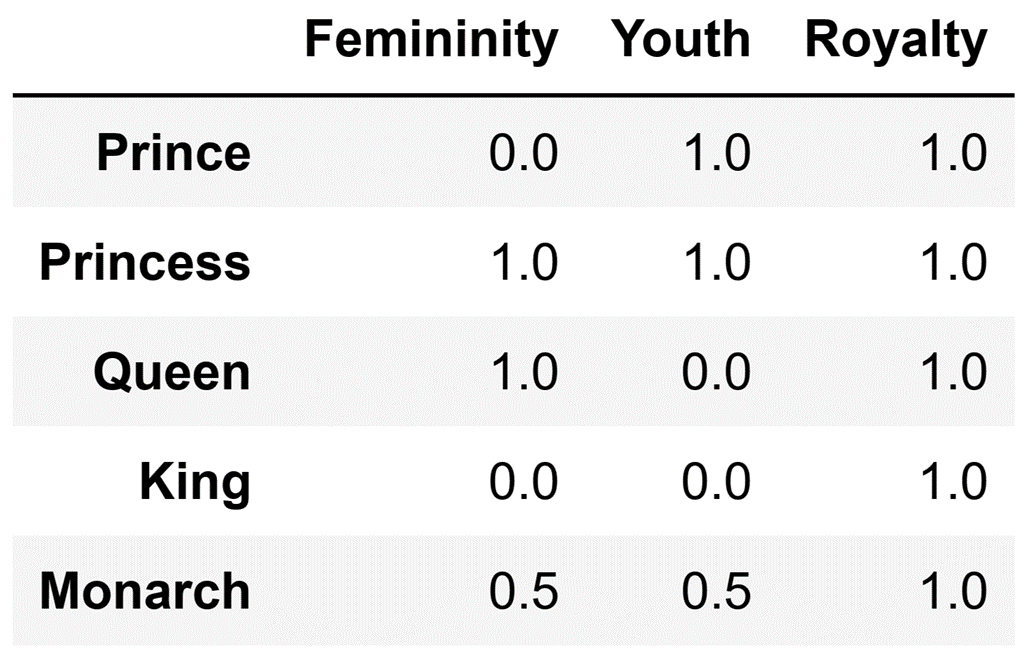
Image Source: Edlitera
In the image above, instead of creating a separate column for each word, I created a separate row for each word. I defined the words as a combination of characteristics, which leads to several benefits. Firstly, the matrix of values I obtained is much smaller. Secondly, I have more non-zero values than zero values in each vector (in this example, this is not true for the word "King,” however this is a byproduct of my use of only three features to create vectors for words). Finally, it ensures that similar words will have similar vectors, as their values for different characteristics will be similar.
What are Analogies in Word Embeddings?
Aside from the previously mentioned benefits of word embeddings, there is another hidden benefit of representing words as vectors in the form of embeddings. Vectors can operate like addition and subtraction, meaning that you can essentially add and subtract embeddings to calculate the embedding for another word.
For instance, I can obtain the embedding for "Prince" from the embeddings for "Queen," “Princess,” and "King.” I’ll first calculate the difference between the "Princess" and "Queen" vectors, which carries information about the relationship between those two words. Let's call that vector the "difference vector.“ Assuming that the difference between the "Princess" and "Queen" vectors is similar to the difference between the "Prince" and "King" vectors, I can simply add my "difference vector" to the vector for "King" to get the vector for "Prince.“
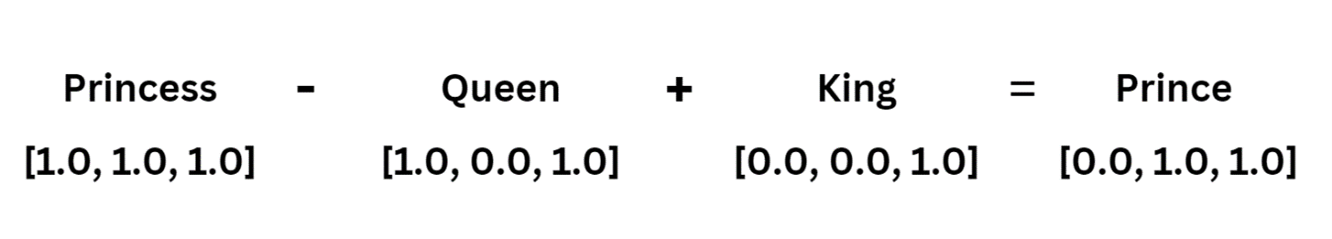
Image Source: Edlitera
How Word Embeddings Work in Large Language Models
Word embeddings are an essential component of Large Language models that play a crucial role in NLP tasks. Large Language models, such as OpenAI's GPT-3, have been trained on massive amounts of text data to understand the nuances of language and generate human-like responses. These models require an efficient way to represent words in a high-dimensional space so that they can be used for various NLP tasks like language translation, sentiment analysis, and text classification.
- Venturing Down the Rabbit Hole of AI: An Interview With ChatGPT
- How Modern AI is Paradoxically Intelligent
From the many advantages of word embeddings I've mentioned previously, the most important one for Large Language models is the ability to capture the semantic relationships between words. This is what allows Large Language models to understand the context and meaning of words in a sentence to generate human-like responses. In addition, word embeddings can also help to handle out-of-vocabulary words.
Running into out-of-vocabulary words (OOV) is a common problem in NLP. These are words that are not present in the training data and are not recognized by the machine, which can result in inaccurate predictions or errors in NLP tasks. Traditional methods of word representation, such as the Bag-of-words method, often ignore or represent OOV words as special tokens. This approach does not capture the context and meaning of the word, which is a problem since sometimes a single word can change the overall meaning of a sentence.
Word embeddings offer a more effective solution to handle OOV words. Instead of ignoring or representing OOV words as special tokens, word embeddings represent them as vectors by leveraging the context of the surrounding words. This is achieved by using the trained word embeddings to map the OOV word to a vector representation that is similar to the vectors of the words in the surrounding context.
Let's imagine that the OOV word is "boots" and the surrounding context is "I bought a new pair of _____ yesterday, because my previous pair was not meant for snowy weather.“ Instead of ignoring the word, I'll instead assign it a vector value. I'll search through the English language vocabulary and find other words that typically appear in the same context and assign a vector similar to those words to my missing word. That way, instead of replacing all missing values with the same vector, or ignoring the word altogether, I increase the chances of my model understanding the sentence. This approach improves the performance of NLP tasks such as language translation, sentiment analysis, and text classification, where OOV words are common.
Human language is a very complex and nuanced system that can sometimes be hard for even humans to navigate, and that makes it extremely challenging to a Machine Learning model to understand. In the beginning, methods such as the Bag-of-words method were used to create numerical representations of text that you could feed to your model, however this method, and other similar methods, are severely limited by the fact that they are not able to capture the complex relationships between different words.
In contrast, word embeddings provide a more sophisticated way of representing language by capturing the contextual relationships between words and facilitating analogical reasoning. The impact of word embeddings on not only Large Language models but on NLP in general cannot be overstated, as word embeddings have proven to be an essential part of helping computers understand human language and generate human-like text.

