

Table of Contents
In this article, you’ll learn the three most common ways to add columns to a Pandas DataFrame. I'll teach you the code you need to add a column, what happens in the background when you do it, and give examples of situations where you’ll use each way of adding columns to your DataFrames.
- Intro to Pandas: What Is a Pandas DataFrame and How to Create One
- Intro to Pandas: How to Analyze Pandas DataFrames
Columns in your DataFrames mainly represent features or variables. Knowing how to add a new column to an already created DataFrame is crucial since you often need to add new features to your data, whether it’s completely new data or something calculated based on data already in the DataFrame.
Let's first create a DataFrame so we have something to add columns to.
import pandas as pd
# Create a dictionary of data
data = {
'Name': ['Alice', 'Bob', 'Charlie', 'David'],
'Age': [25, 30, 35, 40],
'Occupation': ['Engineer', 'Doctor', 'Lawyer', 'Teacher'],
'Hobbies': ['Reading', 'Swimming', 'Cycling', 'Cooking']
}
# Create a Pandas DataFrame from the dictionary
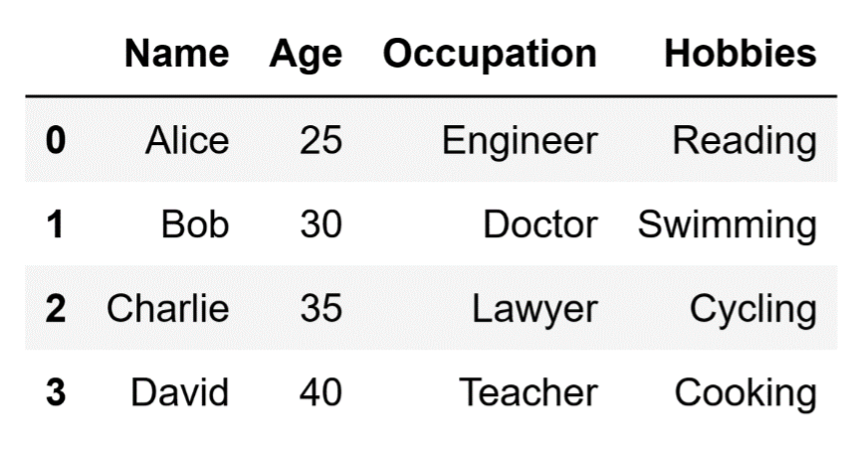
df = pd.DataFrame(data)The DataFrame that we just created looks like this:
A DataFrame.
Image source: Edlitera
Article continues below
How to Add a List of Values as a New Column
The most straightforward way to add a column is to specify a new column name and assign it a list of values. When you do this, you're directly modifying the DataFrame, and the list of values gets transformed into a new column. Let's add each person’s location to a new column of our DataFrame.
# Add a new column named 'Location'
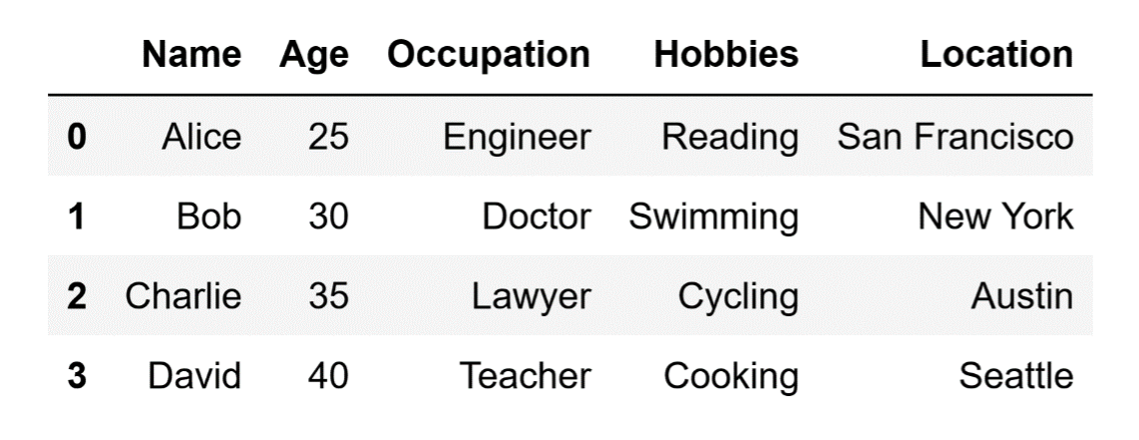
df['Location'] = ['San Francisco', 'New York', 'Austin', 'Seattle']After adding this new column, our DataFrame will look like this:
The DataFrame with an additional Location column.
Image source: Edlitera
The way this works in the background is straightforward. When you add a new column this way, Pandas first checks if the column you are trying to add already exists in the DataFrame. In this case, it checks whether there is a column named "Location" in it. Pandas will overwrite the existing column with the new data you supplied if such a column exists. If not, it will create a new column with the specified values and add it to our DataFrame.
This method is helpful in scenarios where you have a simple list of values you'd like to add as a new feature or variable in your DataFrame. For example, you might have collected new data that you want to add to your existing DataFrame or computed new values based on existing columns that you want to include for further analysis.
However, there are two things you need to keep in mind when adding columns to your DataFrame like this. Firstly, the list length must match the number of rows in the DataFrame, or Pandas will raise an error. Secondly, the data type in the list should be consistent. Whenever you add data to a DataFrame using this method, Pandas will try to infer the data type automatically, but mixed types can sometimes lead to unexpected behavior.
How to Add a Column with a Default Value
Sometimes, you need to add a new column to your DataFrame, but you don't have the actual data that will be in that column. Basically, you want to set up a template to fill in later. In these cases, you can initialize a new column with some default value that will act as a placeholder.
For instance, let's say that we want to add a column to our DataFrame that describes each person's marital status. At this point, we don't know what that marital status is, so we will create a new column with the value "Unknown" in all the rows. We can do this using the following code:
# Add a new column with a default value
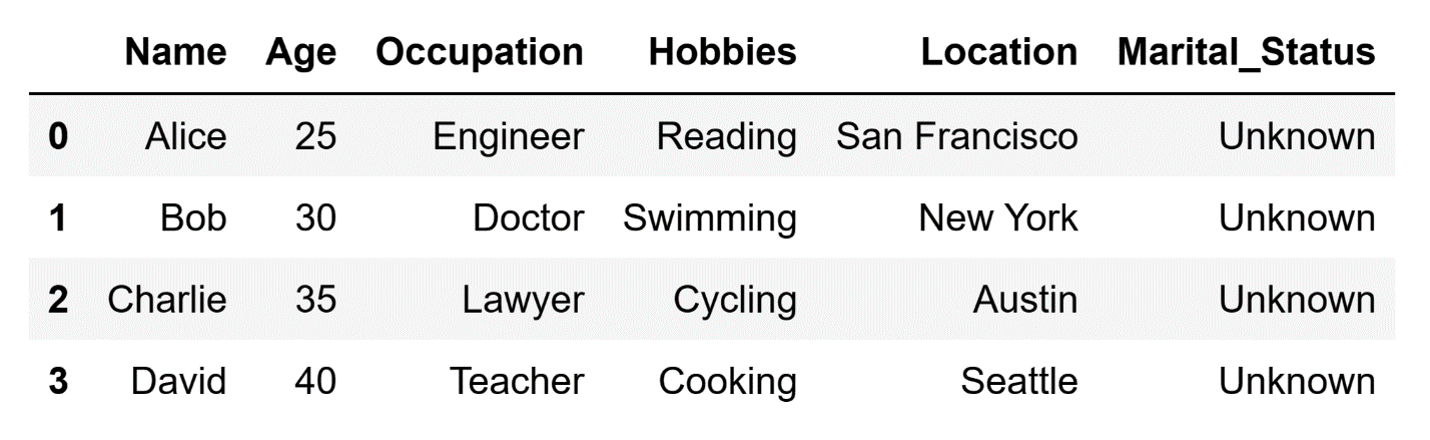
df["Marital_Status"] = "Unknown"After running this code, our DataFrame will look like this:
The Marital_Status column with a default value.
Image source: Edlitera
In the background, Pandas again checks whether a column with that particular name already exists. If it does, it will overwrite the values in that column with the specified placeholder value. If it doesn't, it will create a new column with the placeholder value in each row.
There are two situations where you’ll usually add columns like this to a DataFrame. Firstly, when you plan on joining your DataFrame with another DataFrame that has that particular column (in this case, "Marital_Status"), this will help you combine the two DataFrames. Secondly, if you don't yet have the data that should be in the column, you can create the column with a placeholder value and then later overwrite the data in it with the actual values. Essentially, you’re making a template that you will fill in at a later time.
When using placeholder data, there are a few things to keep in mind. First, you want to make sure that the placeholder values are the same data type as the data that will ultimately populate that column because Pandas infers the data type of a column when it is created. Second, this approach is not necessarily good if your DataFrame is very big. If your DataFrame has, e.g., 300,000 rows, adding a placeholder value to each row will consume a lot of memory, so make sure you are okay with the added memory overhead before doing it.
How to Add Columns Using Series and Arrays
The last way to add columns to a DataFrame is by integrating an already existing Pandas Series or a NumPy Array into a DataFrame.
For instance, let's say that I want to add two new columns to my DataFrame: one column representing how many hours a person works a week and another defining how many years of experience a person has. The data I need for creating the "Workload" column is stored in a Pandas Series, and the data I need for making the "Years_Experience" column is stored in a NumPy Array.
Let's first create this Pandas Series and this NumPy array:
import numpy as np
# Create a Pandas Series that contains data
# about the workload of each person
workload = pd.Series([40, 55, 50, 38])
# Create a NumPy array that contains data
# about how many years of experience each person has
years_experience = np.array([5, 8, 10, 12])To add these two to my original DataFrame as new columns, I can use the following code:
# Add "Workload" and "Years_Experience"
# to our DataFrame
df["Workload"] = workload
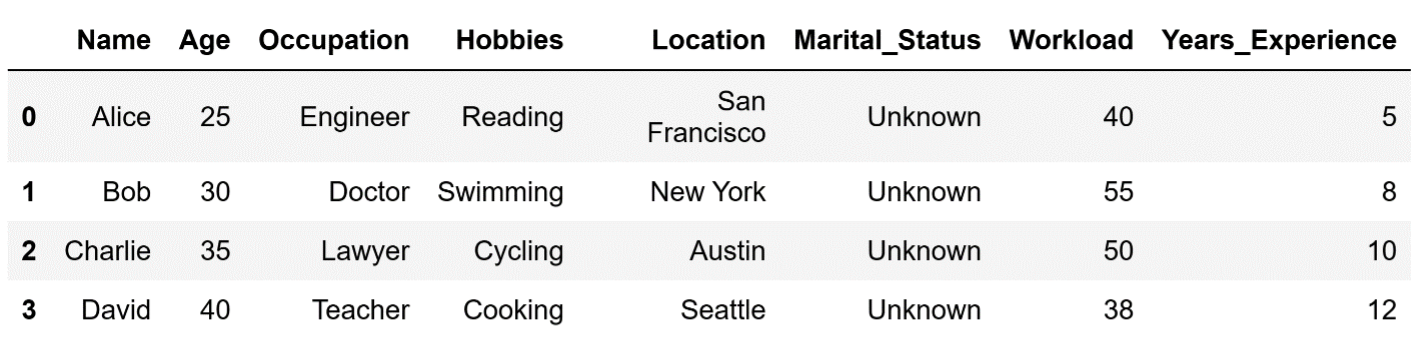
df["Years_Experience"] = years_experienceAfter running this code, our DataFrame will look like this:
The DataFrame with added Workload and Years_Experience columns.
Image source: Edlitera
In the background, Pandas first checks the length of the Pandas Series or NumPy array and ensures it matches the length of our DataFrame. If it doesn't, it will raise an error. If it does, Pandas will continue and check whether a column with the specified name already exists. If the column exists, it will overwrite it with the new data. If it doesn't, it will create a new column and store the data in it. As always, when creating a column, Pandas will infer the new column's data type based on the Pandas Series or NumPy array used to create the new columns.
Adding columns using Series and Arrays is what you’ll typically do when performing any type of data processing. For instance, after you've completed an analysis or calculation on your existing DataFrame, you often need to store these results. If your calculations result in a Pandas Series or NumPy Array, directly adding these as new columns is convenient. You can also seamlessly add columns to your DataFrame without converting the data structures if you are working with external libraries that return Series or Arrays.
This way of adding columns to a DataFrame is prevalent in machine learning: in machine learning workflows, it's common to create new features based on existing ones, and you often end up with Series or Arrays that need to be incorporated back into the original DataFrame.
- The Ultimate Guide to Data Processing with Python
- What Are the Most Common Types of Machine Learning Styles
When creating new columns from Pandas Series objects or NumPy Arrays, there are a few things you need to keep in mind. First, make sure the Series or Array you are using to create the new column is the same length as the DataFrame to avoid index errors. Second, make sure the data type of your Series or Array is compatible with the DataFrame. Finally, as with adding any new column, be careful not to overwrite existing columns accidentally.
After reading this article, you’re familiar with the three main ways to add data to a Pandas DataFrame. You’ve also learned how each process works and when to use each method, so you’re ready to start adding columns to your Pandas DataFrame.

