
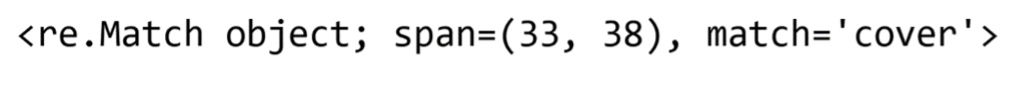
![Image of the result list variable ['In the advanced Python course we cover many different topics. ', 'We cover topics such as concurrency, asynchronous programming and web ', 'scrapping, but also topics such as modules, packages ', 'iterators and generators.']](https://res.cloudinary.com/edlitera/image/upload/c_fill,f_auto,/v1683384477/blog/ymv7les8k1malilnsoco)
![Image of the result ['In the advanced Python course we cover many different topics. \nWe cover topics such as ', ', asynchronous programming and web \nscrapping, but also topics such as modules, packages\niterators and generators.']]](https://res.cloudinary.com/edlitera/image/upload/c_fill,f_auto,/v1683384505/blog/anb7bjwkxkyea80a7ge7)

![Image containing the result ['hold.']](https://res.cloudinary.com/edlitera/image/upload/c_fill,f_auto,/v1683384950/blog/rmwhprv2iwxesm7d9jhk)

![Image containing the result ['ease', 'please']](https://res.cloudinary.com/edlitera/image/upload/c_fill,f_auto,/v1683385407/blog/h2u99mdxnmfwdtne3kwb)


Table of Contents
In our ever-changing digital world, the capability of computers to efficiently understand and handle human language is essential for numerous applications that simplify our lives. With the advent of generative AI models like ChatGPT, the possibilities for Deep Learning models seem almost endless. While these models are undoubtedly powerful, they aren't always necessary to solve problems. Many people forget that Natural Language Processing (NLP) was already a well-developed field before Deep Learning came into play. For tasks like cleaning text data or extracting specific portions of text, using AI models can be overkill. In such situations, using a smaller, more focused library designed specifically for managing text data is wiser. Various libraries are available in different programming languages, but the unifying principle underlying all these text-preprocessing libraries is the notion of Regular Expressions (RegEx).
- Venturing Down the Rabbit Hole of AI: an Interview with ChatGPT
- Self-Attention in Natural Language Processing: The Complete Guide
- Natural Language Processing and its Applications in the Finance Sector
What Is RegEx?
At its core, RegEx is a sequence of characters that represent a specific search pattern. These characters can incorporate literals, metacharacters, character classes, quantifiers, and grouping constructs. Each component plays a crucial role in defining the search pattern's intricacies and helps fine-tune the desired results.
The versatility of RegEx makes it ideal for a wide range of applications, including:
- Text processing
- Data validation
- Search operations
- Web scraping
In text processing, RegEx is used to extract, filter, and manipulate text data. Text processing operations include, for example, extracting specific data, filtering data, and transforming text from one format to another.
RegEx is often used in data validation to ensure user input meets specific formatting and content requirements. This validation process helps maintain data integrity and prevents potential errors or security vulnerabilities. Everyday data validation tasks using RegEx include checking password strength, and validating phone numbers or email addresses.
Search operations include, for example, analyzing log data, navigating code repositories, and mining text data. Developers often need to craft precise search patterns to easily find and analyze pertinent information. RegEx is popular for this purpose because it is highly effective in locating specific patterns within large datasets.
Finally, RegEx is also essential for creating web scrapers. You can use RegEx to extract valuable information from websites or web applications in web scraping. For example, you can use it to ensure that the HTML, XML, or any other markup language is parsed correctly, so that the scraper can successfully return information from websites.
How to Use RegEx in Python
Using RegEx to find patterns is not restricted to any one programming language. On the contrary, RegEx has found its way into many different programming languages, such as Python, Java, or C++. It is even used in text editors and other tools to streamline tasks like data validation, text processing, and search operations.
In this article, I will focus on explaining how you can use RegEx in Python, but the main concepts are the same no matter what programming language you are using—only the syntax is a bit different when you are using another programming language.
In Python, you can implement RegEx through the re module.
The re Module: Functions and Patterns
Python's re module enables pattern matching for string operations using regular expressions. It comes pre-installed as part of the Python Standard Library. The syntax we use consists of two parts:
- Functions
- Patterns
The interaction between the two is simple: you define a search pattern, then use a function to apply the pattern to perform tasks such as searching, matching, or replacing.
- Intro to Programming: What Are Functions and Methods in Python?
- Intro to Programming: What Are Packages in Python?
Functions
The re module contains many different functions that you can use to work with text data, but you will probably get the most use out of the following four:
- findall()
- search()
- split()
- sub()
Article continues below
How to Use the findall() Function
The findall() function returns a list of all non-overlapping occurrences of the pattern in the text we are analyzing. I’ll give you a simple example of the findall() function to demonstrate how it works. This example also shows you how to use the functions even if you don’t know how to formulate search patterns. First, I need to import the re module:
# Import what we need
import reNext, I’ll define the example text data. I will define it as a multi-line string, to emulate how raw text data typically looks before you process it.
# Define example text data
text_data = """In the advanced Python course we cover many different topics.
We cover topics such as concurrency, asynchronous programming and web scraping, but also topics such as modules, packages
iterators and generators."""Now that I have my example text data, I can use the findall() function to determine how often the word "topics" appears in my text.
# Find how many times
# the word "topics" appears in our text
list_of_occurrences = re.findall("topics", text_data) If I take a look at what is currently stored inside the list_of_occurrences variable, I will see the following result:
As you can see, the word "topics" appears three times in our example text data. Do note that I am using an exact word in this case, so that is what the findall() function is looking for and storing in a list. Later on, when I go over search patterns, you will see how different search patterns make it easy to create a list of all words with a specific attribute, such as words that contain only four letters, or only capitalized words.
How to Use the search() Function
The search() function searches the text for the first occurrence of a defined pattern or word you entered. To be more precise, the function returns a match object, which contains certain properties and methods that allow you to access various information about the match that was found. But what exactly is a match? Simply put, a match means that the part of a string that you were searching for has been found in the text. Note that even when a part of a string appears multiple times in your text, the search() function will only create a corresponding match object for the first occurrence.
Let's look at an example. I will search for the word "cover" in the example text data that I created above:
# Search for the first occurrence
# of the word "cover" in our text
match = re.search("cover", text_data)The code above will store the following in the match variable:
The match object I get as a result tells me a few things. Firstly, it tells me that it found a match. Secondly, it tells me where it found it by providing a tuple containing the match's start and end position in the original string.
To extract this information from the Match object, you can use the following two methods:
- span() - Returns a tuple containing the start and end position of the match inside the original string.
- group() – Returns the part of the string where the match was.
In the example above, span() returns the tuple (33, 38), while group() returns the word “cover.” If you use a search pattern instead of searching for a particular word, the situation is slightly different, as you will see later in this article.
How to Use the split() Function
The split() function splits the string into a list of substrings based on the specified pattern. You’ve probably already used the split() function without being aware, even if you are just starting out with Python. For example, a typical pattern used with split() is "\n" which signifies a new line.
When I enter the "\n” pattern into the split() function and apply it to the example text data, I will get back a list of four strings since the original multi-line string consists of four rows.
# Split on new line
result_list = re.split("\n", text_data)The result, stored in the result_list variable, looks like this:
Of course, you can use split() for more than just patterns. For example, I can split on a single word:
# Split on word "concurrency"
result_list = re.split("concurrency", text_data)The result I get is:
How to Use the sub() Function
The sub() function replaces all occurrences of the pattern in the string with the specified replacement string. To give an example of the sub() function, I’ll replace all occurrences of the word "topics" with the word "concepts" in the example text data.
# Substitute the word "topics"
# with the word "concepts"
new_text_data = re.sub("topics", "concepts", text_data)After I perform this operation, the example text data is going to look like this:
How to Use Patterns in RegEx
A pattern, often called a search pattern, is a sequence of characters that describes what you are searching for. It can include literal characters, character classes, quantifiers, anchors, and grouping constructs. In general, however, a search pattern consists of three parts:
- Metacharacters
- Special sequences
- Sets
Until now, I have used whole words as search patterns, but by creating various combinations of metacharacters, special sequences, and sets, I can build intricate search patterns to solve complex problems with RegEx functions.
How to Use RegEx Metacharacters
Metacharacters are characters that carry a special meaning in the syntax of regular expressions during pattern processing. You can use them to, for example, define search criteria. The most important RegEx metacharacters are:
|
Metacharacter |
Use/meaning |
|
[] |
Used to form a set of characters |
|
\ |
Used as an escape sequence for escaping special characters (for example, \d for digits) |
|
. |
Any character except a newline |
|
^ |
Starts with |
|
$ |
Ends with |
|
* |
Zero or more occurrences of a character |
|
+ |
One or more occurrences of a character |
|
? |
Zero or one occurrence of a character |
|
{} |
Specified number of occurrences |
|
| |
Either or |
|
() |
Capture or group |
I’ll demonstrate how to use metacharacters with three examples. To start, I will create some example text data:
# Define example text data
text_data = "Sensors XGB-100 and XGY-107 recorded value above the threshold."As the first example, I will search for all non-overlapping occurrences of lowercase letters between "a" and "o" (inclusive) in the text_data string and return them as a list.
# Find all non-overlapping occurrences of lowercase letters between "a" and "o"
result = re.findall("[a-o]", text_data)Running the code above creates the following list:
['e',
'n',
'o',
'a',
'n',
'd',
'e',
'c',
'o',
'd',
'e',
'd',
'a',
'l',
'e',
'a',
'b',
'o',
'e',
'h',
'e',
'h',
'e',
'h',
'o',
'l',
'd']As a second example, I will replace all numbers in my string with the letter “N.”
# Replace all numbers with the letter N
result = re.sub("\d", "N",text_data)Running the code above creates the following string:
Finally, as the third example, I will search for the first occurrence of the string "XG" followed by any five characters in my example text.
# Search for the first occurrence of the string "XG"
# followed by any five characters
result = re.search("XG.{5}", text_data)Running the code above returns the following Match object:
How to Form Special Sequences
You can form special sequences by combining a backslash ( \ ) with a character that holds special meaning. Depending on which character you attach to the backslash, you will get different results. The most common combinations are:
|
Combination |
Returns a match if |
|
\A |
some character(s) are at the beginning of string |
|
\b |
some character(s) are at the beginning or end of a word |
|
\B |
some character(s) are NOT at the beginning or end of the word |
|
\d |
a string contains digits |
|
\D |
a string does NOT contain digits |
|
\s |
a string contains a white space |
|
\S |
a string does NOT contain a white space |
|
\w |
a string contains any word characters (a to Z, 0-9, or underscore _) |
|
\W |
a string does NOT contain any word characters |
|
\Z |
specified characters are at the end of the string |
I will use the same sentence I used in the metacharacters example to demonstrate. Let's first try to find all the digits that appear in our string and create a list:
#Create a list of the digits that appear in the text
result = re.findall("\d", text_data)The result I get by running the code above is:
Next, let's see how you can check if a part of a word is at the end of the example string.
# Check if a part of the word is at the end of the example string
result = re.findall("hold.\Z", text_data)Running the code above returns the following result:
What Are RegEx Character Sets?
Sets are formed by placing characters inside a pair of square brackets. What you put inside the brackets is the most important part. The most commonly used sets are:
|
Set |
Returns a match |
|
[bwcd] |
if one of a group of the characters inside the square brackets is present |
|
[a-e] |
for any character, alphabetically, between the first and second letter inside the square brackets |
|
[^asd] |
for any character except the ones in the square brackets |
|
[0123] |
if any of the digits inside the square brackets are present |
|
[0-9] |
any digit between the first mentioned digit and second mentioned digit inside the square brackets |
|
[0-7][0-1] |
for any two-digit numbers from the first combination to the second (e.g., 00 and 71) |
|
[a-zA-Z] |
for any character between a and z, lower case or upper case |
|
[+] |
for any + in a string, and this also applies to similar characters such as *, ., |, (), $ and {} |
I’ll show you how to implement these with a few examples of character sets. To demonstrate, I will use the following example text data:
# Create example text data
example_text = "The concept of digits(0123456789) is actually relatively easy for little kids to grasp."First, I’ll demonstrate how you can search for all non-overlapping occurrences of any character that is not "c," "d," "e," or "." in the first 15 characters of our example text data.
# Find all non-overlapping occurrences of any character that is not "c", "d", "e", or "."
# in the first 15 characters of the text data
result = re.findall("[^cde.]", example_text[0:15])Running the code above returns the following result:
You can also use sets to do much more complex things, like replacing all non-alphabetic characters, except for empty spaces, with an exclamation mark “!”.
# Replace all non-alphabetic characters, except for empty spaces, with !
result = re.sub("[^a-zA-Z ]","!", example_text)Running the code above returns the following result:
How to Create Complex RegEx Search Patterns
The true power of RegEx is a byproduct of the fact that you can combine metacharacters, special sequences, and sets, which allows you to create very complex search patterns.
For example, let's say that I have the following sentence:
"Eat say ease sparrow please"
I want to extract all words containing the "ea" substring in them. To do so, I can use the following pattern:
([^\s]*ea[^\s]*)This pattern may look confusing at first glance, but if you break it down, it is actually quite simple. So let's take a look at the basic building blocks of this pattern.
- (...) – Represents a group of characters that matches the pattern "(" represents the beginning of the group, while ")" represents the end of the group.
- [^\s] – Will match any character other than a space.
- [ ] – Are used to describe lists of characters.
- ^ – Signals an exclusion.
- \s – Is what we use to match with empty spaces.
- ea – Represents what we are interested in finding
- * – Indicates that the character or group of characters immediately to the left should be matched 0 or more times.
Let's put everything together and run it in Python. First, I need to define the example text data.
# Define example text data
text_data = "Eat say ease sparrow please"Now I can use the search pattern above, combined with the findall() function, to find all words that contain "ea" inside of them in the example text data.
# Get words that contain "ea"
words = re.findall(r"[^\s]*ea[^\s]*", text_data)Running the code above leads to the following list being stored in the words variable:
Of course, this is just one example of a search pattern. There is an almost infinite number of combinations that you can use to create the search pattern you need to solve your problem. With practice, creating Regex patterns will become second nature.
To sum up, regular expressions are a handy tool for working with text in Python. They can be a real lifesaver when dealing with large data sets because they let you search for, extract, replace, and manipulate text data quickly and easily. Even though the RegEx syntax might seem tricky at first, taking the time to learn it is definitely worth it for any Python programmer. Regular expressions are becoming increasingly valuable in today's world as NLP and chatbots become more prevalent. RegEx can be a powerful tool in building intelligent systems that can understand and respond to human language. That’s why having a solid understanding of RegEx in Python can open up many doors for developers looking to work in the exciting and rapidly growing field of NLP.
Read next: Is Bias in NLP Models an Ethical Problem? >>

