






Table of Contents
COVID-19 caused many companies to rethink current practices and try something new. For some, “something new” meant a first attempt at integrating artificial intelligence (AI). But for others that have already implemented AI into regular business, the next step might be implementing edge computing. Edge computing is an especially good idea for companies whose practices involve using computer vision.
Many people have heard of computer vision and edge computing but, in case you haven’t, I’ll give some definitions. Put simply, edge computing is the practice of processing data in close proximity to the data source, which generally makes the processing faster and more efficient. Computer vision, on the other hand, is a method of data processing in which computers analyze images or videos to gain information. While the idea of migrating computer vision software to edge devices is nothing new, the implications of it for businesses have never been greater. Whether for small-scale or industrial-level applications, the benefits of processing data near its source should not be ignored.
In some cases, running computer vision software on the edge is a necessity and not a luxury. Time-sensitive tasks, such as autonomous driving, have zero tolerance for problems that emerge when data processing is not done close to the source. In these cases, using the time and resources to implement edge computing makes sense. But computer vision on the edge has become popular lately in many industries. Let's take a look at why.
What is Computer Vision?
Computer vision can be described as the process of teaching a computer to analyze visual data in a similar way to us as humans. Computer vision can find patterns in visual data that you can't, which is useful in a variety of ways. Some applications in which computer vision is used today are:
- Automatic inspection in manufacturing applications
- Assisting humans in identification tasks
- Controlling robots
- Detecting events
- Modeling objects and environments
- Navigation
- Medical image processing
- Autonomous vehicles
- Military applications
These are just a few uses for computer vision and, while it's sometimes compared to the field of digital image processing, computer vision is much more than that.
In its early development, computer vision was meant to mimic human visual capabilities. The goal was to use computer vision to allow robots to “see.” However, with time, programmers found many other uses for it. The accomplishments of computer vision can mostly be attributed to how popular the topic is in the deep learning community.
Today, artificial intelligence (AI) is responsible for many scientific breakthroughs, so creating efficient and effective computer vision models is one of the main tasks for deep learning researchers. With so many scientists and scholars working on improving the computer vision models that already exist—and some working on creating new models—it is no wonder that the quality of computer vision systems has seen rapid growth. Alongside natural language processing, computer vision is probably the most popular application of AI today.
While there are many applications of computer vision, all of them can be described as variations of one of the four basic computer vision tasks. The four basic computer vision tasks are:
- Recognition
- Motion Analysis
- Scene Reconstruction
- Image Restoration
Each task can be dissected into many different sub-tasks. However, generally speaking, these are the four problems you'll typically seek to solve using computer vision. Out of all of them, the most popular task is probably recognition.
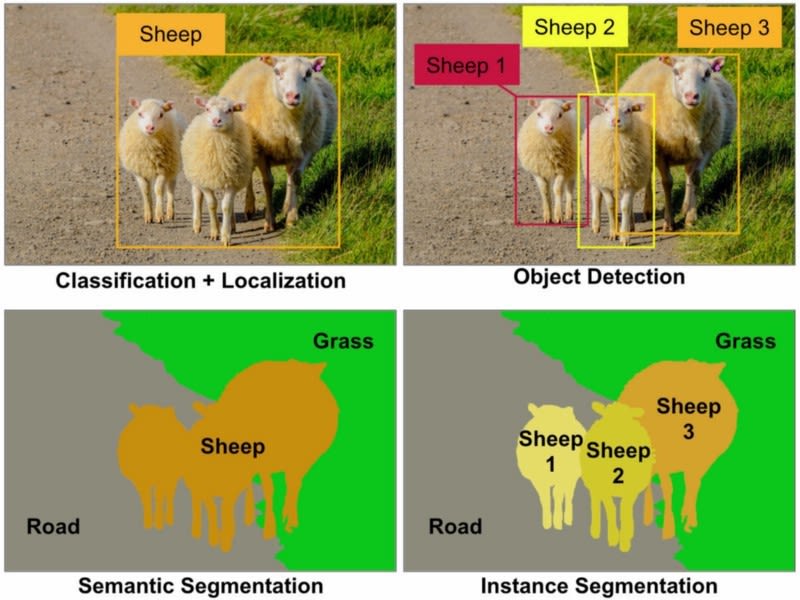
Recognition covers other general tasks, such as classification, object detection, and image segmentation (both semantic segmentation and instance segmentation).
Object detection and segmentation
Image Source: Parmar, Ravindra. “Detection and Segmentation through ConvNets.” Medium. Towards Data Science, September 1, 2018. https://towardsdatascience.com/detection-and-segmentation-through-convnets-47aa42de27ea.
More specialized tasks that you can classify under object recognition include pose estimation, facial recognition, and 2D code reading:
Pose estimation
Image Source: Babu, Sudharshan Chandra. “A 2019 Guide to Human Pose Estimation with Deep Learning.” Nanonets. Nanonets, August 5, 2019. https://nanonets.com/blog/human-pose-estimation-2d-guide/.
As in all other fields of research, the speed at which computer vision advances has had its ups and downs. Comparing where computer vision is now to where it was ten years ago highlights the rapid rate of growth the field has enjoyed in recent years. However, to achieve the best possible results, computer vision development has made some compromises, mostly in the form of computing power.
New computer vision models, although more accurate, require more processing power. While this doesn't mean that researchers completely disregard performance, sometimes processing power does become less of a priority than model accuracy. In these situations, you might say that temporarily disregarding efficiency for the sake of achieving progress in scientific research is fine. The same doesn't typically apply when it comes to industrial and other applications.
But even the best model is useless if it isn't efficient enough. Efficiency is especially important for computer vision models as they come with their own set of problems. A lack of data affects computer vision models in the same way that it is an omnipresent problem for all deep learning models. Aside from a lack of data, the three most common problems for computer vision models are:
- Bandwidth
- Speed
- Network Accessibility
These three problems have been solved, to a certain degree, as edge computing technology advances. To explain the connection between edge computing and computer vision, let's first take a look at the basics of edge computing.
Article continues below
Want to learn more? Check out some of our courses:
What is Edge Computing?
In general, edge computing is a method of computing that reduces the distance between the location of the computer and the location of the data used by the computer. The benefit of edge computing is that it typically results in faster response times while also saving on bandwidth.
The Gartner Glossary defines edge computing as "a part of a distributed computing topology where information processing is located close to the edge, where things and people produce or consume that information." The important takeaway about edge computing is that it occurs near the data source, instead of relying on a remote data center.
Edge computing sprung into existence once major Cloud providers such as Amazon, Google, Microsoft, and IBM, realized the limits of the growth space in the Cloud. They also saw that almost everything that could potentially be centralized already was. They concluded that to further expand their area of influence and open up new opportunities, they must expand to the “edge.”
Edge computing by itself has many different applications, and computer vision is just one of them. But edge computing brings several benefits to computer vision, including improved response time, reduced bandwidth usage, and an increased level of security. I'll delve deeper into each of these in the next sections.
What is Response Time?
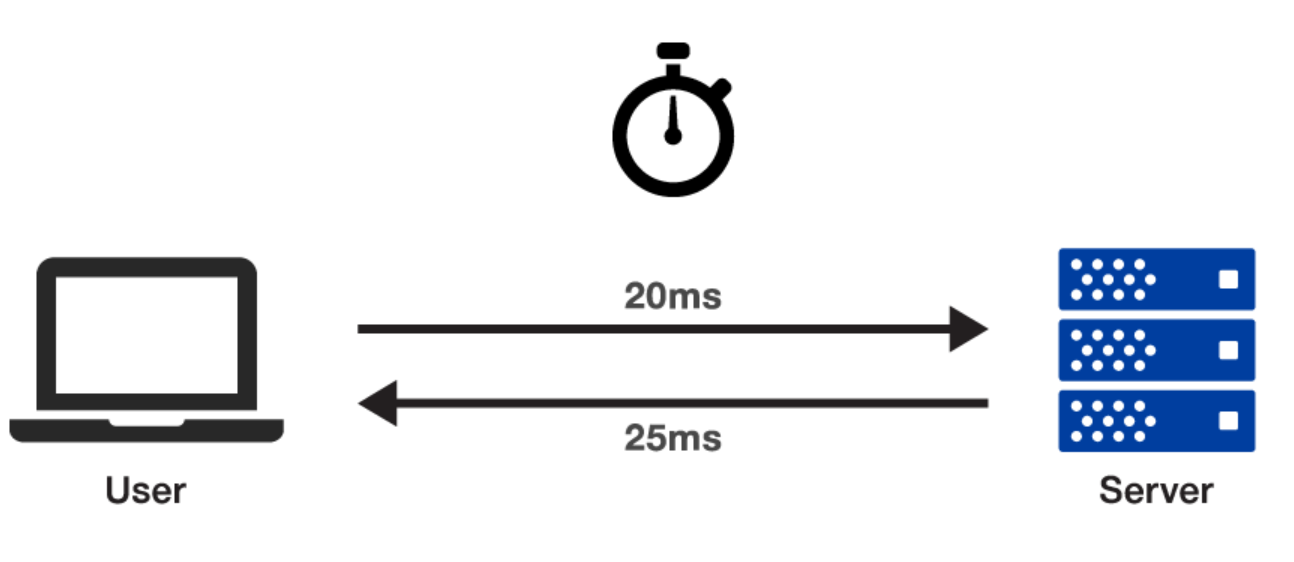
Computer scientists use the term latency to describe the delay between the action of a user and an application's response to that action. Latency is often referred to in networking terms as the total round trip time needed for the travel of a data packet. The importance of reducing latency in computer vision cannot be overstated. When computer vision systems operate, a certain period of time (called a buffer) occurs between gathering data and having that data processed and ready to use. Because many systems rely on the Cloud for data storage, the buffer time is the time it takes for data to travel from the measuring device to the Cloud and back.
Buffering time in itself is not necessarily problematic. In fact, in some cases, having some small buffer time doesn't actually matter. Yet for a lot of applications of computer vision, latency needs to be as small as possible. In ideal situations, latency is reduced to zero for operation in real-time.
For example, time-sensitive applications, such as the operation of robots or self-driving cars, have little to no tolerance for the latency that can sometimes occur when connecting to the Cloud. It's preferable to use edge computing for computer vision to reduce latency. Since edge devices don't depend on a central data center or network bandwidth, they are not affected by latency.
Bi-directional network latency is between 30 milliseconds and 100 milliseconds in North America and Europe, and as high as 200 milliseconds in Asia and Africa. Having the freedom to ignore delays of these magnitudes is extremely important. If 100 milliseconds doesn't seem like a big deal to you, just remember how long you sometimes wait for a webpage to load. Or, ask yourself if you'd be okay with your surgeon or self-driving car taking that much time to decide on something important.
Speed is not the only benefit of edge computing. Because they are network independent, edge devices can be deployed in the parts of the world that do not possess the necessary network infrastructure for computing in the Cloud. And better yet, by using edge devices you can ensure that some critical operations, such as a camera recognizing that somebody is armed, will be performed even if a network gets temporarily disabled.
Latency = 20ms + 25ms = 45ms
Image Source: Mahmud, Saief. “How to Choose the Best Hosting Location for Your Website.” VernalWeb, May 23, 2021. https://www.vernalweb.com/blog/choose-the-best-hosting-location-for-your-website/.
What is Bandwidth?
Bandwidth is often described as the maximum throughput of a network. Because their analytical services are close to their users, AI and other analytical tools can run on the edge. This increases operational efficiency by a large margin. Comparing the bandwidth used when using servers located on a local edge network against the bandwidth used when transmitting over the internet shows that using edge devices results in a noticeable bandwidth savings.
Throughput
Image Source: Keary, Tim. “Latency vs Throughput - Understanding the Difference.” Comparitech, June 8, 2021. https://www.comparitech.com/net-admin/latency-vs-throughput/.
What is the Importance of Security in Computer Vision?
Security and privacy are of the utmost importance in computer vision because computer vision systems often work with sensitive data. For example, video data can often contain very sensitive information. Any type of internet transfer or Cloud storage of video data makes it susceptible to access by non-authorized individuals.
Processing video data on the edge means you don't need to send data to the Cloud or store it there. In this way, you reduce the chance that a security breach happens. By using edge computing, you can distribute the risk of exposure across multiple devices. Because all kinds of processing can be performed while disconnected from a central server, it is much more difficult for hackers to hack edge computer systems.
How to Use Computer Vision on the Edge
To migrate computer vision to the edge, you'll need to accomplish a few things. First, you must have a device that can function as an edge device. For computer vision, edge devices with a GPU (graphical processing unit) or VPU (visual processing unit) are preferred. Usually, when talking about edge devices it is often about IoT, or Internet of Things, devices. However, any device that can be configured to assess visual data in order to analyze its environment has the potential to be used as an edge device for computer vision.
Once you have a device, the second step is setting up an application. The easiest way is to deploy the application from the Cloud to the device. Once the application has been deployed, you can disconnect our device from the Cloud and you can process the data the device collects on the device itself. You're probably already very familiar with one device that fits our criteria: the smartphone.
Through the years, smartphones have evolved from devices mostly used as traditional phones to devices where the ability to call others has become secondary. One of the most popular advancements smartphones have enjoyed over standard cellphones are cameras. The quality of cameras integrated into smartphones are only getting better each year. Combine this with modern smartphone processors and you have an ideal computer vision device.
In fact, anyone who builds mobile apps has, to a degree, been building on the edge. It's never been easier to create and deploy a complex computer vision application on a smartphone. This is partly because of how far the hardware used in today's smartphones has evolved. For example, in 2021 Qualcomm announced the Snapdragon 888 5G mobile platform as the processor that will power premiere Android phones. This processor brings advanced photography features like the ability to shoot 120 photos per second at 12-megapixel resolution. Having this much power in an edge device allows developers to create complex applications that can still be run on the edge, while on the smartphone itself.
Computer vision on the edge, on smartphones
Image Source: TechHQ. Smartphones and Facial Recognition. Nothing Personal? How Private Companies Are Using Facial Recognition Tech. TechHQ, June 8, 2020. https://techhq.com/2020/06/nothing-personal-how-private-companies-are-using-facial-recognition-tech/.
Of course, other applications of computer vision at the edge exist that are much larger in scale than mobile phone applications. Applications of computer vision at the edge are becoming more popular in industrial environments, especially in analysis of manufacturing processes. Software deployed on the edge can allow engineers to examine each step of a manufacturing process and detect anomalies in near real-time.
Similarly, the ability to track and record the length of a cycle time for a given process can help easily identify process bottlenecks. Dealing with these bottlenecks can increase the overall efficiency of many manufacturing processes. Using cameras with software deployed on the edge, you can even analyze products on an assembly line and identify ones that are defective.
Detecting problematic products
Image Source: USM. Top 7 Use Cases of Computer Vision in Manufacturing 3. Top 7 Use Cases of Computer Vision in Manufacturing. USM, October 5, 2020. https://usmsystems.com/use-cases-of-computer-vision-in-manufacturing/.
In conclusion, artificial intelligence is more popular than ever. Companies that have already implemented AI are looking for ways to improve their practices. Companies that haven't will most likely use AI sooner or later. So it follows that computer vision, as one of the most developed fields of AI research, is also becoming more widely used than ever before.
Creating a simple computer vision application has become so accessible that even Machine Learning engineers who don't work in the field of computer vision can—with some time and effort—do so successfully. With a little research, they can, for example, create an app that detects if somebody is wearing a mask and then modify that app to run on an edge device. While they might not be as good as professionally designed apps, amateur app accuracy using computer vision can be staggering.
So if an individual can pick up computer vision, why can't a company? The technology for it already exists, and discovering new methods to better work practices should be high priority for a competitive business. Latency issues, bandwidth limitations, and security concerns drive most companies to implement computer vision. While it brings upfront cost, those costs are a valuable investment in the rapidly-approaching future.
Interested in learning more about computer vision? Check out Edlitera's computer vision training courses.

