









Table of Contents
Indexers in Pandas are essential for data manipulation tasks such as data selection, data filtering, and even conditional modifications. There are two main types of indexers. One of them is the loc indexer, which is used for label-based indexing. The other is iloc, which is used for integer-location-based indexing. The focus of this article will be on explaining the usage of iloc in selecting data in Pandas.
What is the .iloc Indexer
The iloc indexer is what is used for integer-location-based indexing. As a matter of fact, iloc itself is an abbreviation for integer-location. Using iloc, data can be selected based on its position in the DataFrame or series, and not based on the index labels. In other words, iloc exclusively uses integer positions for accessing data. As a result, it makes it particularly useful when dealing with data where labels might be unknown or irrelevant.
iloc follows standard Python and NumPy indexing rules, including start-inclusive and end-exclusive notation in slices. In addition, it supports the usage of negative indices. There are multiple ways we can select data using iloc. These are the main ways:
• integer indices
• slices
• lists of integers
Let's demonstrate how we can select data using the iloc indexer. For starters, I am going to create a DataFrame to be used as an example:
import pandas as pd
# Data for the DataFrame
data = {
"Name": ["Alice", "Bob", "Charlie", "David", "Eva", "Frank"],
"Age": [25, 30, 35, 40, 45, 50],
"City": ["New York", "Los Angeles", "Chicago", "Houston", "Phoenix", "Philadelphia"],
"Occupation": ["Engineer", "Doctor", "Artist", "Teacher", "Lawyer", "Chef"]
}
# Creating the DataFrame
df = pd.DataFrame(data)
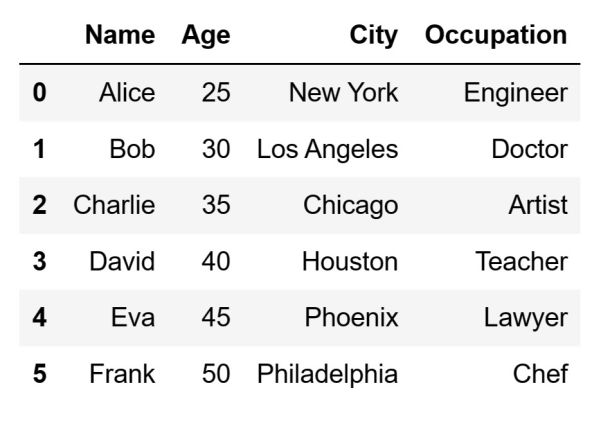
The code above will create the following DataFrame:
Now that we have a DataFrame ready, let's demonstrate how we can perform some common data selection operations using iloc.
Article continues below
Want to learn more? Check out some of our courses:
How to Return a Row as a Series
The need to access data that is stored in a particular row in your DataFrame is frequent Using iloc, we can specify the position of the row in our DataFrame. We can also return that row as a Pandas Series object. For instance, I can select the first row of the DataFrame and return it as a Series using the following code:
# Select the first row
# and return a Series
df.iloc[0]
Running this code will return the following Series:
Keep in mind that the code above will only return the Series. If you wish to use it afterward, you need to store it in a variable:
# Select the first row and return a Series
# Store the series in a variable
first_row = df.iloc[0]
You can certainly select any row in the DataFrame and return it as a series. It doesn't necessarily need to be the first row. For example, we can select the third row and return it as a Series using the following code:
# Select the third row and return a Series
# Store the series in a variable
third_row = df.iloc[2]
The code above will store the following Series inside the third_row variable:
We can even use negative indexing. There is also the possibility to access the last row of your DataFrame and return it as a Series using the following code:
# Select the last row and return a Series
# Store the series in a variable
last_row = df.iloc[-1]
The code above will store the following Series inside the last_row variable:
How to Return Multiple Rows as a DataFrame
If you select multiple rows in a DataFrame using iloc, by defining a slice, you will get back a DataFrame and not a Series. For instance, you can select the second, third, and fourth rows and return them as a DataFrame using the following code:
# Select the second, third and fourth rows
# and return them as a DataFrame
# Store the DataFrame in a variable
df_slice = df.iloc[1:4]
The code above will store the following DataFrame inside the df_slice variable:
Several operations happen in the background when we run the code above. For starters, Python accesses the iloc property of the DataFrame object. Afterward, it interprets the slice notation. In Python, slicing is zero-based, so an index of 1 refers to the second element. The slice 1:4 includes indices 1, 2, and 3, but not 4 (the end index is exclusive). Pandas know exactly which information you are interested in after interpreting the slice notation. As a result, it can create a new DataFrame from them, that we can store in a variable if we want to.
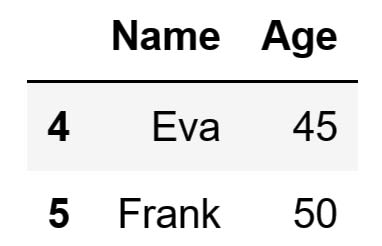
You can certainly use negative indexing to select multiple rows, similar to how you could use it when selecting just one row. For instance, you can select the last two rows and create a DataFrame from them using the following code:
# Select the last two rows
# and return them as a DataFrame
# Store the DataFrame in a variable
df_slice_2 = df.iloc[-2:]
The code above will store the following DataFrame inside the df_slice_2 variable:
How to Return a Column as a Series
We can similarly return a column to how we can return a single row as a Series. The only difference between the two is that the syntax for return columns is a bit more complex. To be more precise, to return a column you technically need to define that you want to return all of the rows of a certain column. If you want to select the first column and return it as a Series you need to define it as a slice, using the following code:
# Select the first column and return it as a Series
# Store the Series in a variable
first_column= df.iloc[:, 0]
The code above will store the following Series inside the first_column variable:
To return this result, a series of steps happen in the background. For starters, Python accesses the iloc property of the DataFrame object. Afterward, it interprets the slice notation. In the slice [:, 0] the colon: signifies the selection of all rows, and 0 specifies the first column. Pandas will process our request and select the first column across all rows. Internally, this involves accessing the underlying NumPy array and extracting the appropriate column. The operation will return a Pandas Series, which will then be stored in a variable.
Similarly, if you want to return any other column, all you need to do is modify the second part of the slice. The first part will still be a colon: so that Pandas is aware of your interest in all the rows from that column. However, the second part will be the index of the column you are interested in. For example, let's select the second-to-last column of our DataFrame:
# Select the second-to-last column and return it as a Series
# Store the Series in a variable
second_to_last = df.iloc[:, -2]
The code above will store the following Series inside the second_to_last variable:
How to Return Multiple Columns as a DataFrame
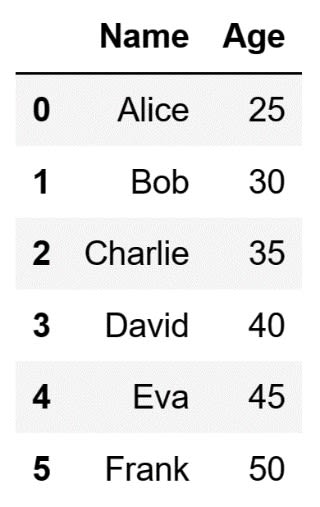
Returning multiple columns is also possible. Doing so will result in a DataFrame, and not a Series. To return multiple columns as a DataFrame, the first part of the code needs to remain as a colon. However, in the second part, you define a slice, instead of defining the index of the column you are interested in. For instance, to return the first two columns you can use the following code:
# Select the first two columns and return them as a DataFrame
# Store the DataFrame in a variable
first_two_columns = df.iloc[:, 0:2]
The code above will store the following DataFrame inside the first_two_columns variable:
What happens in the background is essentially identical to what happens when only one column is selected. The only difference is that, when parsing the slice, Pandas will recognize that we want to access multiple columns and not just one.
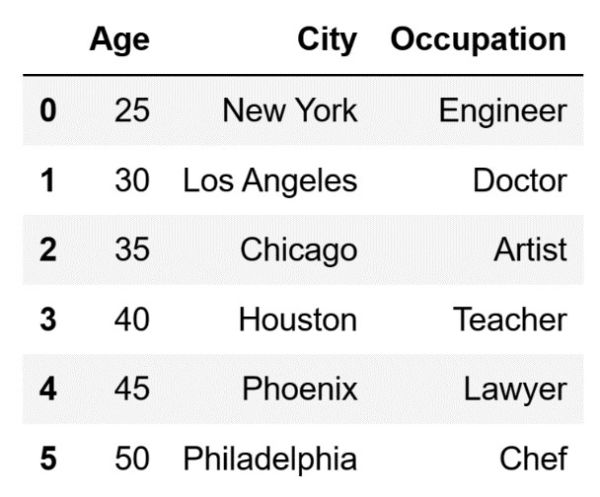
Similar to everything up until now, we can certainly use negative indexing. Let's select the last three columns (all of them except the first one) using negative indexing:
# Select the last three columns and return them as a DataFrame
# Store the DataFrame in a variable
last_three_columns = df.iloc[:, -3:]
The code above will store the following DataFrame inside the last_three_columns variable:
- Intro to Pandas: What is a Pandas DataFrame and How to Create One
- Intro to Pandas: How to Analyze Pandas DataFrames
How to Return Specific Rows and Columns as a DataFrame
Using slices to select certain rows from certain columns is the most advanced way of using the iloc indexer. This is something that will happen frequently. Selecting only certain rows from some columns is especially easy. This is done if you merely change the first part of the slice so that it isn't a colon: but instead points to the rows you are interested in. For instance, let's select the last two rows of the first and second columns:
# Select the last two rows of the first two columns
# and return them as a DataFrame
# Store the DataFrame in a variable
df_complex_slice= df.iloc[4:, 0:2]
The code above will store the following DataFrame inside the df_complex_slice variable:
Finally, selecting data from non-consecutive rows and columns is the most advanced way of selecting data using iloc. To do so, inside of the square brackets you input two other square brackets. One of them will be a list of the indices of the rows you are interested in, and the other will be a list of the column indices you are interested in. For instance, you can select the first and last row of the second and last columns:
# Select the first and last row of the second and last column
# and return them as a DataFrame
# Store the DataFrame in a variable
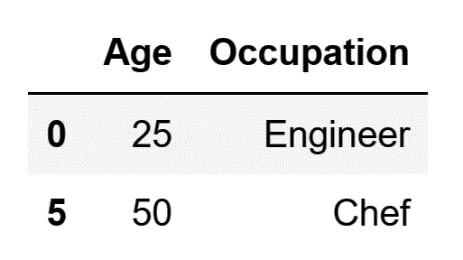
df_complex_slice_2= df.iloc[[0, -1], [1, -1]]
The code above will store the following DataFrame inside the df_complex_slice_2 variable:
As can be seen in the example above, when you are defining the lists of the indices you are interested in you can use both positive and negative indexing.
- Intro to Pandas: How to Add, Rename, and Remove Columns in Pandas
- How to Remove Columns from a Pandas DataFrame
- How to Add Columns to a Pandas DataFrame
This article covered how you can select data stored in DataFrame using integer-location-based indexing via the iloc indexer. It demonstrated how you can select single rows and columns and return them as Pandas Series objects. In addition, it explained how you can select multiple rows and columns and return them as Pandas DataFrame objects. A future article is going to cover how you can access data using label-based indexing via the loc indexer.

