



Table of Contents
Once you learn the basics of NumPy, you are ready to start learning about the most popular package for data analysis and processing in Python: the Pandas package. As the most prominent package for working with data in Python, Pandas has everything you need to import data, process it, visualize the results, and much more.
In this series of articles on Pandas, I will go over all of the intricacies of Pandas. Starting with why Pandas is so popular and what structures you can use in Pandas to store data.
Why Use Pandas?
Before I start talking about how the Pandas package works, I'll explain why you should use Pandas. To be more precise, let's talk about what are the prerequisites for data processing and what the different functionalities you require a data processing library to have so that you can use it to process data in a fast and efficient manner.
First of all, you need to be able to import and export data. Data is nowadays stored in a lot of different formats, so our library of choice must be able to import and export data to multiple different data formats. Often you'll need to import data stored in CSV files, Excel files, text files, and databases, and after processing the imported data you'll also have to be able to export data to those same formats (maybe even create a simple dashboard from the processed data).
Second, you need to be able to process data stored in a table. Most of the data you will work with is tabular data, so Pandas must be able to perform various operations such as:
- Merge data tables
- Filter data
- Pivot data
- Modify data
- Reshape data
- Add columns
- Remove columns
- Rename columns
The Python package you choose must be able to perform all the operations above (add columns, rename them, etc.) to be an efficient library tool for data processing.
Of course, the library you plan on using must also be able to work with different data types. This is not limited to just numbers and text data - you must be able to process other types of data such as dates. Ideally, you'll want the package you work with to also be able to create visualizations. Because humans are visual creatures it is often a much better idea to represent the results of some data analysis in a visual format.
Finally, the package you plan on using must be able to handle large files. Nowadays, mainly because of the Internet, there is a lot of data available for analysis. It is not uncommon to run into extremely large datasets, therefore the package you plan on using must be able to handle files that are tens of gigabytes in size (maybe even more).
Pandas satisfies all of the previously mentioned conditions, which is why it is the first choice for people who want to analyze data and process it in Python.
Article continues below
Want to learn more? Check out some of our courses:
How to Install Pandas
Pandas, like any other package in Python (aside from those that come already preinstalled with Python), need to be installed before you can use it. There are a few ways of installing Pandas. To be more precise, it can be installed using either pip or Anaconda.
- Intro to Programming: How to Get Your Computer Ready to Run Python
- Intro to Programming: How to Write and Run Code
The standard way of installing Pandas is using pip, as it is the default Python package manager. To install Pandas using pip all you need to do is open a console or a terminal and type in :
pip install pandasAnother way you can install Pandas is using conda, a package management system that makes installing different packages easier to install. If you plan on installing Pandas using conda, then you need to type in the following into a console or a terminal:
conda install pandasAfter installing Pandas, you should be able to import it the same way you import any other package, using the import statement:
import pandasIn practice, Pandas is typically imported under the alias pd. This is just a convention, you don't necessarily need to do it, but it is what most programmers do because it makes your code easier to read:
import pandas as pdWhat Are The Basics of Pandas?
Pandas is a Python package for working with panel data, which is also how it got its name. It tries to replicate the look and feel of data tables in Excel and SQL databases. The primary data structures it exposes are Series (one-dimensional structures) and DataFrames (two-dimensional structures). A Series is the equivalent of a column in a table, while the DataFrame is the equivalent of the table itself. As a tool built on top of NumPy, it takes advantage of all the performance improvements and other benefits that NumPy brings to the table.
What Are The Basics of Pandas Series?
As previously mentioned, a Pandas Series object represents one-dimensional data as a column of data. You can think of them as an array of data combined with an array of labels. The array of data can be data that is of multiple different types. The array of labels is what we call an index.
As you will see later on, when you have multiple Pandas Series that share an index, you get what is called a DataFrame. So you can essentially treat a Pandas Series as a column of a Pandas DataFrame.
In fact, as you will see later on, when you extract a column from a Pandas DataFrame you'll typically get a Pandas Series.
Image Source: Screenshot of Panda Series from a Pandas DataFrame, Edlitera
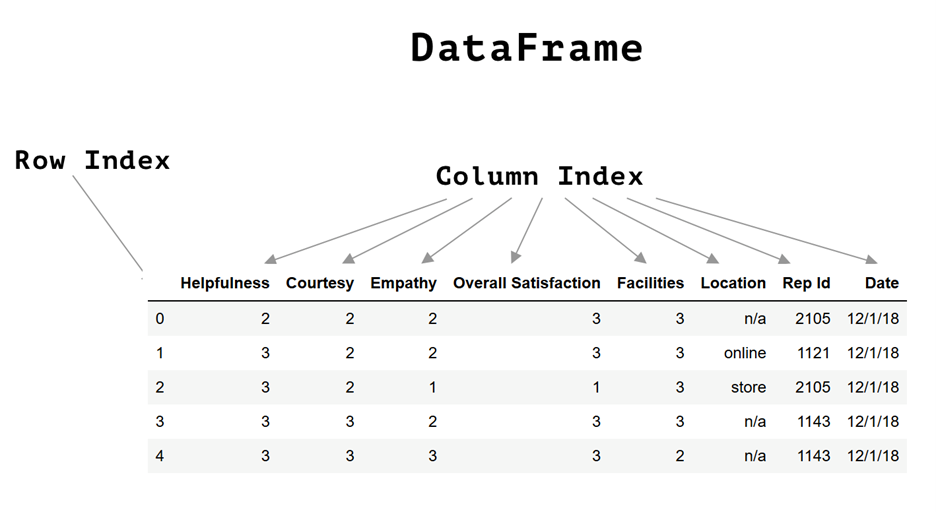
What Are The Basics of Pandas DataFrames?
DataFrames are fundamental Pandas objects. They represent two-dimensional data in a way very similar to what you get when you take a look at an Excel sheet. Essentially, you have a table that contains one or multiple columns, where each one of those columns is actually a Pandas Series object. The columns represent different features of a particular dataset, but all of them share the same index.
The concept of an index is very important here. There are two types of indices:
- Row index – a label that is assigned to a row
- Column index – a label that is assigned to a column
An index is an object that can be used to access data stored in a DataFrame. In the subsequent articles of this series, we will demonstrate how you can, if you want to, even created nested indices.
Image Source: Screenshot of a DataFrame, Edlitera
In this article, I went over what is Pandas and why do you will want to use Pandas. There are many prerequisites a data processing package must satisfy, and Pandas satisfies all of them, which is why it is the premiere package for data analysis and processing in Python.
I also covered the fundamentals of the basic building blocks of Pandas, the Pandas Series, and the Pandas DataFrame. In the following articles, I will explain how you can use these two objects in-depth, focusing on how to create them, how to store data in them, how to modify the data that is stored in them, and much more.

