

![[('tok2vec', <spacy.pipeline.tok2vec.Tok2Vec at 0x12e9d9ef5e0>), ('tagger', <spacy.pipeline.tagger.Tagger at 0.12e9d9df770>), ('parser', <spacy.pipeline.dep_parser.DependencyParser at 0x13068631ee0>), ('attribute_ruler', <spacy.pipeline.attributeruler.AttributeRuler at 0x130687af8c0>), ('lemmatizer', <spacy.lang.en.lemmatizer.EnglishLemmatizer at 0x130688499c0>), ('ner', <spacy.pipeline.ner.Entity.Recognizer at 0x13068631c40>)]](https://res.cloudinary.com/edlitera/image/upload/c_fill,f_auto,/v1684395244/blog/cel3vuovhj2sop6drlgq)






Table of Contents
Out of all programming languages, Python is the best suited for building deep learning and natural language processing applications and has seen a surge in popularity as a result. However, with the surge in popularity of Python and natural language processing, there are now numerous libraries and frameworks available for developers to use in building natural language processing applications, making it difficult to choose the right one for a particular project. As a result, developers need to carefully evaluate the requirements of their project and choose the library that best meets their needs. In this article, I will focus on introducing SpaCy, one of the most popular natural language processing libraries out there, and explaining how you can use it in your projects.
What is SpaCy?
SpaCy is an open-source library designed and developed by Matt Honnibal from Explosion AI. It markets itself as "the package for industrial-strength NLP in Python". As a library, it stands out from other NLP libraries due to its focus on performance, ease of use, and industry readiness. While other open-source libraries, such as Gensim, are also designed to handle NLP tasks very efficiently at at scale, they are typically designed to handle problems such as topic modeling, creating word embeddings, and document similarity. On the other hand, SpaCy excels in other tasks, such as:
- linguistic analysis
- part-of-speech tagging
- dependency parsing
- named entity recognition
Therefore, it is probably more apt to compare SpaCy to a library such as NTLK rather than a library such as Gensim. While there is some overlap in functionality, libraries such as SpaCy and Gensim are generally complementary rather than direct competitors.
Even though SpaCy can be compared to libraries such as NLTK, because it handles similar problems, it is worth mentioning that the main design goals of SpaCy are different and emphasize different aspects of NLP. SpaCy is not as flexible and does not provide an extremely comprehensive range of functionalities, however, what it does provide is extremely optimized and very user-friendly.
Characteristics of SpaCy
As I mentioned previously, SpaCy was not created to be used for research purposes, teaching, or even prototyping. Instead, it is an excellent choice for those who value performance, practical applicability, and ease of use.
Article continues below
Want to learn more? Check out some of our courses:
Fast and Efficient
SpaCy was designed to process large volumes of text extremely quickly by using Cython. Cython allows developers to write Python code that is compiled into optimized C code. This approach combines the flexibility of Python with the speed and efficiency of C. By leveraging optimized C code, SpaCy can perform critical NLP tasks such as parsing and tokenization, and of course many others, very quickly. SpaCy is also fast because of its use of pipeline architecture. We'll talk more about that later, when I demonstrate how customizable SpaCy is.
Comparison of the efficiency of SpaCy and NLTK.
Image Source: Edlitera
Easy to Use
SpaCy has a high-level interface that simplifies performing NLP tasks. Common NLP tasks such as tokenization, part-of-speech tagging, and named entity recognition can be performed with a few lines of code. The syntax to perform these operations is very simple, to the point where even beginners who are completely unfamiliar with SpaCy could, at a glance, figure out what certain lines of code do.
In addition, SpaCy also provides many features that simplify working with text data. Possibly the most useful of those is built-in support for common file formats such as CSV files, JSON files, and Markdown.
Customizable
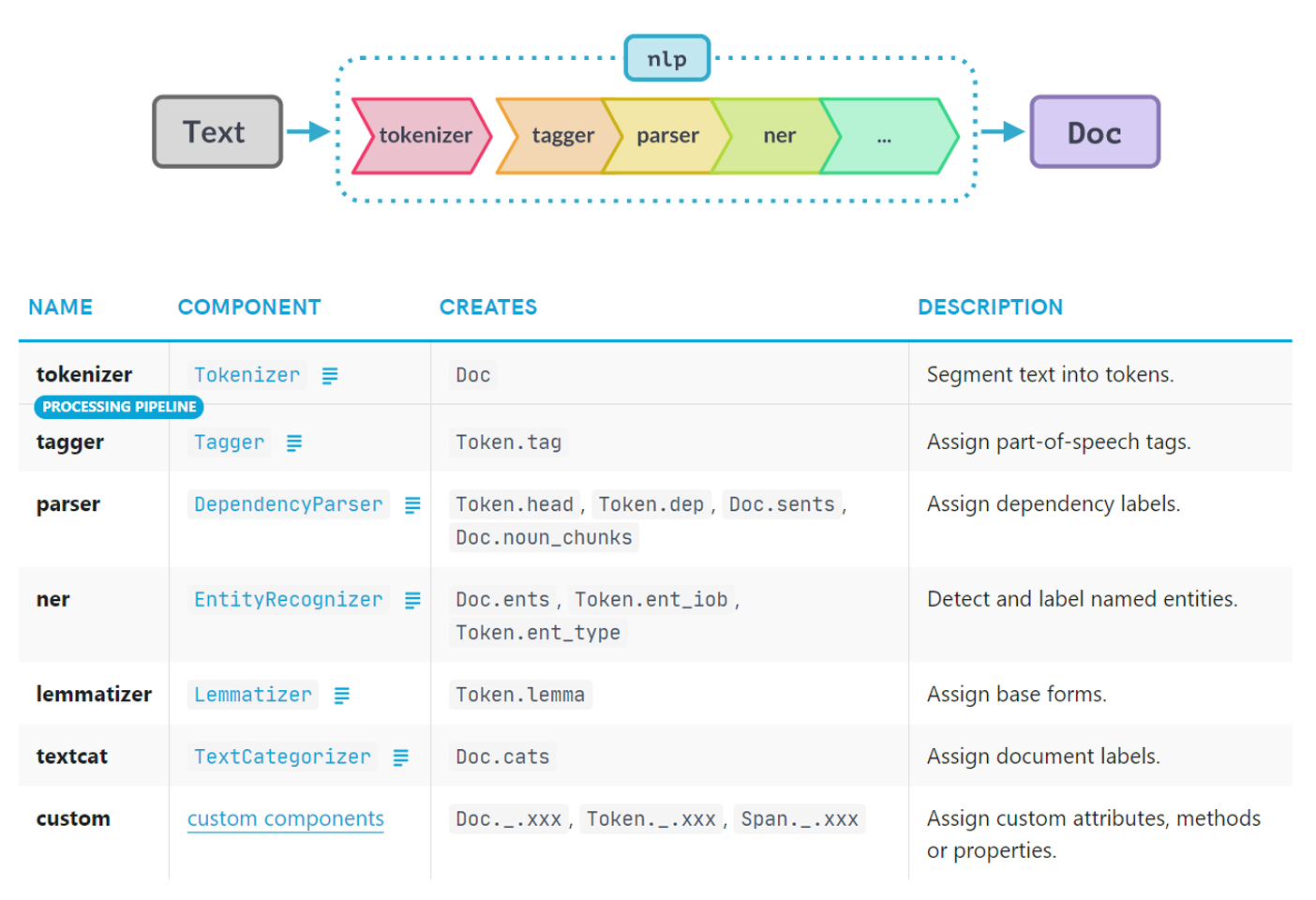
One of the main reasons why SpaCy is so popular is its ease of customization. This is a by-product of one of the key design features of SpaCy: the pipeline architecture. The idea of creating a pipeline that you can push data through is not novel, but the approach SpaCy takes is.
In Spacy, pipelines are implemented as objects. Each pipeline is an instance of the spacy.pipeline.Pipeline class, which defines the sequence of processing steps that are applied to the input text. The Pipeline class acts as a container for a series of components, where each one of those components is responsible for a specific NLP task. The order of components in the pipeline object corresponds to the order in which the NLP tasks are performed.
Components of the SpaCy pipeline.
Image Source: Edlitera
For example, in a typical Spacy pipeline, the first component handles tokenization, splitting text into individual words or tokens. These tokens are then sent to the next component, which might handle part-of-speech tagging or named entity recognition. The order of components matters, because it affects how text is processed and the results produced. For instance, if you want to perform named entity recognition before part-of-speech tagging, you'd need to change the component order. The pipeline order also influences the performance and accuracy of NLP tasks. Lemmatization, for example, should be done after part-of-speech tagging, because a word's lemma depends on its part of speech.
There are 80 already trained pipelines for over 27 languages available for use in Spacy, but users can also create custom pipelines. The Pipeline object provides several methods for modifying and extending the pipeline. For example, you can add or remove components from the pipeline, customize the processing parameters for each component, or add custom components to perform additional NLP tasks. Later in this article, I will demonstrate how to build one of these pipelines and how to modify it.
Easy to Integrate
SpaCy is designed to integrate well with other Python libraries, especially those used for working with machine learning models. This is very important, because most NLP problems are solved using machine learning models. SpaCy integrates very well with both TensorFlow and PyTorch, two of the most popular deep learning frameworks. It also integrates great with Scikit Learn, the most popular classic machine learning library. SpaCy also works great together with popular data analysis and processing libraries, such as Pandas. In general, if you are working in the field of NLP, you are unlikely to run into a popular library that SpaCy doesn't integrate well with.
- What is the Difference Between Machine Learning and Artificial Intelligence?
- The Ultimate Python Pandas Cheat Sheet
- How to Build an Image Augmentation Pipeline with Albumentations and PyTorch
How to Create a Text Processing Pipeline with SpaCy
The first thing you need to do is install SpaCy. The easiest way to do this is by running the following command in the terminal:
pip install spacyAlternatively, you can run !pip install spacy in a cell of a Jupyter notebook. That will also install SpaCy in your Python environment.
That is all there is to installing SpaCy. To demonstrate how SpaCy works I will create a pipeline and use it to process a few examples of text data. To be more precise, I will use a pre-trained model to do so, but I will also later demonstrate how easy it is to modify that pre-trained model.
As I mentioned previously, SpaCy offers a lot of pre-trained pipelines. In SpaCy, the terms "pre-trained models" and "pre-trained pipelines" are often used interchangeably, but they refer to slightly different concepts.
Pre-trained models are neural network models that have been trained on large amounts of data to perform specific natural language processing (NLP) tasks, such as part-of-speech tagging or named entity recognition.
Pre-trained pipelines are pipelines that include one or more pre-trained models as components. They are designed to work out of the box and can be easily customized to suit specific use cases.
The reason why these two terms are often used interchangeably even though they are technically different things, is because in a large number of cases, users just load a single model and create a pipeline of it. Basically, because the model is the only component of the pipeline, they are sometimes treated as the same. This means that, for most users, the difference between a pre-trained model and a pre-trained pipeline is only a matter of semantics.
For this example, I will use the en_core_web_lg SpaCy model. To use a model you must first download it. To download the SpaCy model run the following command in the terminal:
python -m spacy download en_core_web_lg This pre-trained model was trained on English text data, so that is what I am going to use to demonstrate how it works. Let's create some example text data:
# Define some example text data
text = """Whose woods these are I think I know.
His house is in the village though;
He will not see me stopping here
To watch his woods fill up with snow.
My little horse must think it queer
To stop without a farmhouse near
Between the woods and frozen lake
The darkest evening of the year.
He gives his harness bells a shake
To ask if there is some mistake.
The only other sound’s the sweep
Of easy wind and downy flake.
The woods are lovely, dark and deep,
But I have promises to keep,
And miles to go before I sleep,
And miles to go before I sleep."""The text above is a very famous poem by Robert Frost called "Stopping by Woods on a Snowy Evening." Now that I have some text data to work with, it is time to demonstrate how easy it is to use SpaCy to apply various operations on it. First, I need to import SpaCy:
import spacyAfter importing SpaCy I need to create a pipeline. To create a pipeline I can use the load() function. This function loads in a SpaCy model and automatically creates a pipeline from it. I will use this function to create a pipeline from the model I downloaded earlier:
# Load a SpaCy model
# and create a pipeline from it
pipe = spacy.load("en_core_web_lg")When the load() function loads in a model, it will break it down into its components, and create a pipeline that consists of those components. Let's take a look at what components our pipeline is made up of by accessing the pipeline attribute:
# Display what the pipeline is made up of
pipe.pipeline
Running the code above returns the following result:
The pipeline I loaded can:
- create embeddings
- perform part-of-speech tagging
- parse text data
- perform lemmatization
- perform named entity recognition
Now that the pipeline is ready, I can pass the example text data through it. When you pass text through a SpaCy pipeline, SpaCy automatically creates a Doc object that represents the analyzed document. In this case, the document is the string that contains the poem. To pass the text data through the pipeline, the only thing I need to do is call the pipeline using the text data as the input, which I can do using the following code:
# Create a Doc object
document = pipe(text)The code above will push the text data through the pipeline. The text data will be processed by the components of the pipeline in the order in which they are present in the pipeline, and will then create a Doc object. This is where the beauty of SpaCy lies. At this point, all operations are done, so accessing useful information is as easy as accessing an attribute of the Doc object.
SpaCy's Doc object is a container for processing and accessing linguistic annotations. It contains a sequence of Token objects, each representing an individual token (word, punctuation, etc.) in the text. To access any token I can simply reference the Doc object and ask it to return a token that is connected to a certain index. Let's ask for the second token of the example text data:
# Access the second token
document[1]The code above will return the following result:
Of course, I can also easily return multiple tokens:
# Access multiple tokens
document[1:5]The code above will return the following result:
Consequently, to get back a list of all the tokens, I can use the following code:
# Get all token objects
tokens = [token for token in document]The code above will store the following in the tokens variable. As the output is longer, this is just part of it:
The list continues and includes all of the tokens that were created when I passed the poem through the pipeline. This, by itself, is already useful, but this is just the beginning. Remember that each one of these tokens is a Token object. Therefore, each token has many attributes, such as:
- text - the original text of the token
- lemma_ - the base form (lemma) of the token
- is_space - True if the token is an empty space, False otherwise
- is_stop - True if the token is a stop word, False otherwise
- is_punct - True if the token is a punctuation mark, False otherwise
- is_digit - True if the token is a digit, False otherwise
- like_num - whether the token resembles a number (e.g., "10" or "ten")
For instance, the first word of the poem is a stopword. Let's prove that by running the following code:
# Check if the first word is a stopword
document[0].is_stopThe code above will return the following result:
This feature of SpaCy, where each token is a special object with different attributes, is more useful than it appears to be. For instance, I could clean the text data by removing tokens with certain attributes. Let's clean the text data by removing stopwords, empty spaces, and punctuation marks:
# Clean text data
cleaned_tokens = [token for token in document if not
token.is_space | token.is_punct | token.is_stop]
The code above will store the following in the cleaned_tokens variable. Because the output is longer, I will show only part of it:
Do note that the list above contains Token objects, and not strings. If you want to get a list of strings, you can access one of the following two attributes of the tokens:
- orth_
- text
Both of these two attributes represent the original text of the token as it appears in the input text. This means that I need to slightly modify the code I used above to get a list of strings instead of a list of Token objects:
# Clean text data and return strings
cleaned_strings = [token.orth_ for token in document if not
token.is_space | token.is_punct | token.is_stop]How to Customize a Text Processing Pipeline with SpaCy
Previously, I demonstrated how you can load a model to create a pre-trained pipeline, and how you can use it to perform some text processing. While most users use these pre-trained pipelines without modifying them at all, this is actually not a good idea. That's because these pipelines contain many components that are not necessarily useful for every single project.
For example, let's say that I just want to tokenize my text, perform POS tagging, perform lemmatization and return my tokens in the form of a list of strings. In that case, I don't need many of the components that are part of the model I loaded earlier. Instead, I am only going to load certain components of the pre-trained model, and create a pipeline out of them.
To be more precise, I will keep the following components:
- tok2vec
- tagger
- attribute_ruler
- lemmatizer
The tagger and attribute_ruler will perform POS tagging, and the lemmatizer will perform lemmatization. We will also keep tok2vec because this component increases the performance of all of the other components. It computes vector representations for the tokens in the input text, which allows it to learn context-sensitive embeddings during the training process, capturing semantic and syntactic information about the tokens in the text. The word embeddings it creates are used as input features by other components in the pipeline. Because these word embeddings carry semantic and syntactic information, they also improve the performance of the other components of the pipeline.
Let's create a pipeline that includes just the three previously mentioned components:
# Create a simpler pipeline that doesn't use all components
simple_pipe = spacy.load(
"en_core_web_lg",
disable=["parser", "ner"])
simple_pipe.pipelineThe code above will return the following result:
Now that I have successfully created the pipeline, I just need to pass the text through it. This will automatically separate the text into tokens, create embeddings, perform POS tagging, and finally, perform lemmatization.
# Create a Doc object
document = simple_pipe(text)To finish, I will create a list that contains the lemmatized versions of all tokens, except for those that are stopwords, punctuation marks, and empty spaces. The code to do this is nearly identical to the code I used earlier to create a list of strings, with one small change: instead of accessing the orth_ attribute to get the original text of the token as it appears in the input text, I will access the lemma_ attribute of the tokens. Fortunately, the lemma_ attribute also returns strings, and not Doc objects.
# Create a list of lemmatized strings
cleaned_lemmas = [token.lemma_ for token in document if not
token.is_space | token.is_punct | token.is_stop]
The code above will store the following in the cleaned_lemmas variable. Because the output is longer, I will show just a part of it:
At first glance, it might look similar to the list of strings I got earlier, but if you inspect it more closely, you will notice the differences between the two lists. For example, the original list of strings contained the string "gives", while this list of lemmas contains the lemma "give" instead.
In conclusion, SpaCy is a top choice for developers, researchers, and others working in the field of natural language processing. Its outstanding performance, user-friendly features, and growing community make it an indispensable tool in the field. It enables users to maximize the potential of language data, optimizing efficiency in industrial pipelines and driving discoveries in natural language processing. In this article, I covered everything you need to know to get started with SpaCy, and also demonstrated how you can perform many common operations in the field of NLP.

![[Future of Work Ep. 2 P2] Future of Learning and Development with Dan Mackey: Automation, ROI and Adaptive Learning](https://res.cloudinary.com/edlitera/image/upload/ar_16:9,c_fill,f_auto,q_auto,w_100/trgtawmebf1mylb4mfb55vazc0li?_a=BACADKBn)