




Table of Contents
We run into situations where we need to remove data from a DataFrame as often as we run into situations where we need to add data to a DataFrame. Therefore, it is important to know how to remove useless rows from our DataFrame. The reasons they are not useful can be either because they are not relevant to our analysis or maybe because they contain corrupted data. In this article, I am going to explain how we remove rows from Pandas DataFrames. I will explain how we can manually specify the rows to drop, and not only that. I will also explain how one can remove rows based on some predefined conditions.
How to Drop Rows from a Pandas DataFrame
There are different ways we can remove rows from a Pandas DataFrame. Based on the technique we use, we either manually specify which data to drop or we do it by defining a certain condition. In the second case, you could argue that theoretically, we are not dropping data as much as filtering our DataFrame. However, I strongly believe that those techniques are still relevant and deserve to be mentioned.
For starters, let's create a simple DataFrame for the purpose of data removal.
import pandas as pd
import numpy as np
# Creating a sample DataFrame for students
data = {
'Student_Name': ['Alice', 'Alice', 'Charlie', 'David', 'Eva', 'Frank', 'Grace', 'Hannah', 'Ian', 'Jane'],
'Math_Score': [92, 92, 78, np.nan, 88, 79, 95, 93, 87, 76],
'English_Score': [85, 85, 89, 90, 92, 75, 95, 88, np.nan, 80],
'Date_of_Birth': ['2005-01-15', '2005-01-15', '2005-03-30', '2005-04-12', '2004-09-05', '2004-12-14', '2005-02-07', '2004-10-25', '2004-08-19', '2005-05-29']
}
df = pd.DataFrame(data)
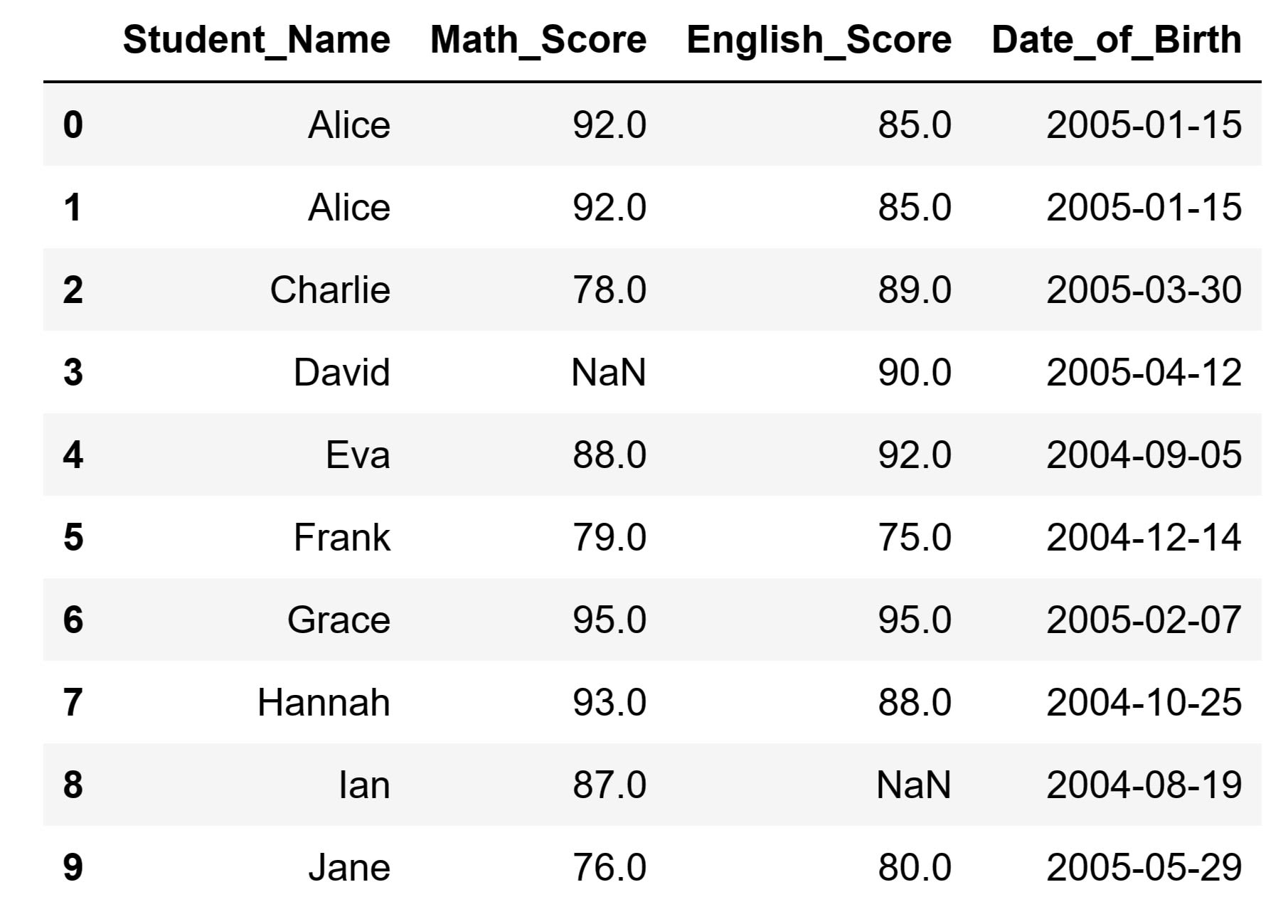
Running the code above will result in the following DataFrame:
As you take a look at our DataFrame, there are a few things you can immediately notice. First, there are missing values in the Math_Score and English_Score columns. Second, there are duplicates in the DataFrame. To be more precise, the second row is a duplicate of our first row. In practice, when we clean data to prepare it for data analysis, we immediately have to deal with the same problems. Let's cover the different techniques we can use to deal with these problems. Let's also explain how we can remove rows from DataFrames in general.
Article continues below
Want to learn more? Check out some of our courses:
How to Drop Rows Using their Index Label
Arguably the easiest way to drop rows, provided you have a clear understanding of which rows to drop, is by referencing their index labels. This way we can remove any row, or even multiple rows, from our Pandas DataFrame. To demonstrate, let's remove two rows from our Pandas DataFrame, the ones with index labels 4 and 5.
# Drop rows with index labels 4 and 5
df.drop([4, 5], inplace=True)
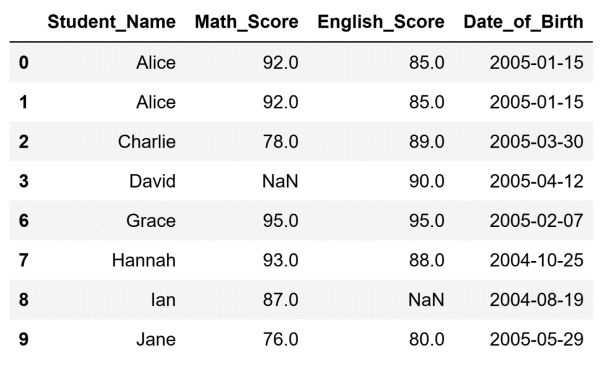
After running this code our DataFrame will look like this:
As you can see, we successfully removed the rows with index labels 4 and 5. To do so, we used the drop() method. This method allows us to enter a list of index labels. Afterward, it will drop the rows connected with those index labels. The inplace argument, when set to True, ensures the changes are applied directly to our original DataFrame.
In the background, Pandas initially checks if the specified index labels, in this case 4 and 5, exist in the DataFrame. If they exist, it removes the corresponding rows from the DataFrame. On the other hand, if any of the specified index labels do not exist, no error is raised. What happens is that the method simply skips that particular index label.
This method is particularly useful in scenarios where you know exactly which are the problematic rows from your DataFrame. If you know that a row connected to a certain index label has outliers, errors, or is no longer relevant you can easily remove it with this technique.
- Intro to Pandas: How to Add, Rename, and Remove Columns in Pandas
- How to Remove Columns from a Pandas DataFrame
How to Drop Rows with Missing Values
You can't always know exactly which rows are problematic. For example, if you are working with a large DataFrame with hundreds of thousands of rows. In such cases, you might run into a situation where a hundred or more rows are missing data. Manually specifying which rows to drop based on an index label is not practical in such a situation.
We, instead, express our intention to drop rows that contain missing data, without concern for their specific index labels. In this case, we are missing data in rows connected to index labels 3 and 8. We can drop these rows without even mentioning their index labels. This can simply be done by referencing that they are missing data:
# Drop rows that are missing data
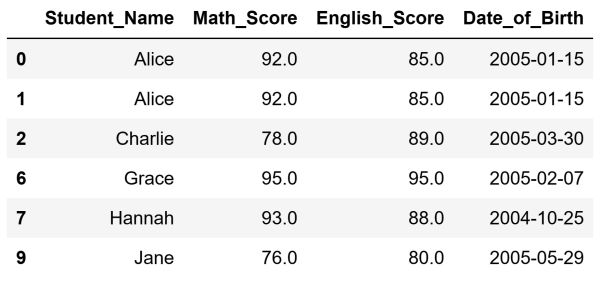
df.dropna(axis=0, inplace=True)After running this code our DataFrame will look like this:
As you can see, we successfully removed the two problematic rows. To do so, we used the dropna() method. The axis argument specifies whether we want to drop rows with missing values or columns with missing values. If set to 0, we drop rows. If set to 1, we drop columns. Once again, the inplace argument, when set to True, ensures that the changes are directly applied to our original DataFrame.
In the background, Pandas scans the DataFrame row by row. For each row, it checks if there are any missing values in it. If there are, it drops the row from the DataFrame.
This method is particularly useful when working with datasets that may have incomplete or corrupted data. The removal of rows with missing values ensures that your subsequent analysis or operations are performed on a cleaner dataset. However, it's essential to be cautious when using this method. The reason for this is that dropping too many rows can result in a significant loss of information. It's always a good practice to first assess the extent of missing values before deciding on a strategy to handle them.
How to Drop Duplicate Rows
In some cases, having duplicate rows in a DataFrame may not be problematic. However, in most cases, you want to avoid having duplicates in your DataFrame. Therefore, it is common practice to remove any duplicate rows you run into in your DataFrames.
In this example, the row with index label 1 is a duplicate of the row with index label 0. Let's remove the duplicate row:
# Drop duplicate rows
df.drop_duplicates(keep='first', inplace=True)
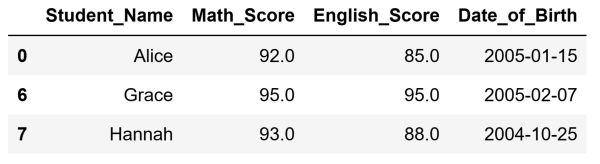
After running this code, our DataFrame will look like this:
As you can see, we successfully removed the duplicate row, the row with the index label 1. This was done with the help of the drop_duplicates() method. The inplace argument, when set to True, ensures that the changes are directly applied to our original DataFrame.The keep argument of the method defines which row we want to keep.
To provide a more detailed explanation, Pandas internally scans the DataFrame row by row, searching for duplicates. In our DataFrame, it will notice that the rows with the index labels 0 and 1 are duplicates of each other. Once it determines this set of duplicates ( there can be more than two duplicates of a row in a DataFrame) it looks at what we defined with the keep argument. If set to 'first', it will keep the row with the index label 0 as that is the first row from our set of duplicate rows that appears in our DataFrame. If set to 'last', it will keep the row with the index label 1 as that is the last row from our set of duplicate rows that appears in our DataFrame. Finally, we can set it to False, which would tell Pandas to remove all rows from the set of duplicates from our DataFrame. In our situation, this means that Pandas would remove both rows from the DataFrame.
The drop_duplicates() method is especially useful when dealing with datasets that could contain redundant data. At times, when merging or combining data from various sources, duplicate rows might be introduced unintentionally. The drop_duplicates method provides an efficient way to clean the dataset. This is achieved by removing these redundant entries, ensuring data integrity.
How to Drop Rows Based on a Condition
Sometimes we want to drop rows from a DataFrame that meet specific criteria. There are two main ways of doing this in Pandas. However, for both, it would be more accurate to say that they actually "filter out" the unwanted rows. In practice, this is not really relevant because we get the result we want. For example, our DataFrame with certain rows removed based on whether they meet some criteria or not.
Let's remove all rows where the student doesn't achieve a Math score of at least 90:
# Filter our problematic rows
df = df[df['Math_Score'] >= 90]
After running this code our DataFrame will look like this:
As you can see, by using standard filtering we successfully removed the problematic rows. Our approach involves defining a condition that will generate a Boolean series (True/False values) for each row in the DataFrame, indicating whether the condition is met. Afterward, we can filter the DataFrame by using this Boolean series. This is done by keeping only those rows where the condition is met. For example, where the value is True. In practice, this drops the rows that do not meet the condition and are unwanted in our DataFrame.
There is one other method we can remove rows through filtering. To demonstrate, let's remove those rows where students don't achieve an English score of at least 90:
# Filter our problematc rows
df = df.query('English_Score >= 90')
After running this code our DataFrame will consist of one student, as the only one to meet all of our criteria:
To filter out the other students we used the query() method. This method allows you to filter a DataFrame using a query string. In the background, Pandas evaluates the provided query string and returns only those rows where the condition is True. Therefore, in our case, Pandas checked the values in the English_Score column and returned True only if the condition was fulfilled(if the score was 90 or above). In practice, this removed two of the final three rows we have in our DataFrame, leaving us with just one row.
In this article, I covered the various ways you can remove rows from your DataFrames. I explained how you can remove rows by manually specifying their exact index labels. In addition, I explained how you can remove them based on a condition, whether it's related to missing data, duplicates of another row, or anything else that will help us clean our data and prepare it for analysis.

